Nem tudom már pontosan mikor, de valószínűleg 1-2 éve volt hasonló feladvány egy Exceles bajnokságon, amellyel ismét csak azt kívánom bemutatni, hogy a megszokott és ismert függvények kreatív felhasználásával egészen hihetetlen kérdésekre lehet egészen hihetetlen megoldásokat adni - azt a bizonyos feladatot emlékeim szerint akkor az összes résztvevő 10 percnél kevesebb idő alatt abszolválta, de ahogy általában lenni szokott, itt már nem a függvények összeállítása, egyszerűen a logika megtalálása a leghosszabb idő.
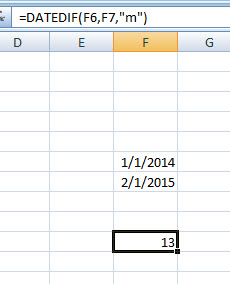
Adott a lenti példa és hozzá kapcsolódóan a feladat: adjuk meg B5:B7 cellákba azt, hogy az azonos sorokban szereplő dátumintervallumok és a B3:B4 cellákban megadott két dátum intervalluma között pontosan hány nap az átfedés!
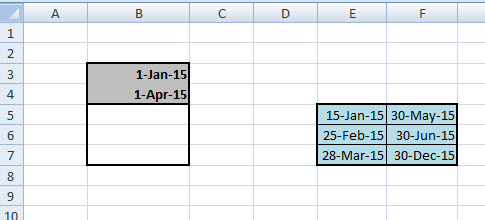 Például az elsőnél mondjuk meg, hogy január 15. és május 30.-a közötti intervallumból hány nap esik január elseje és április elseje közé. Finom kis fejtörő, főleg ha tudjuk, hogy alig néhány percünk van rá - de ha megvan a logika, akkor villámgyorsan összedobhatjuk az eredményt. És ahogy Excelben általában mindig, most sem egyetlen megoldás létezik, a kérdésre a választ ugyanis kis eltökéltséggel még egy IF-fel is ki tudjuk csikarni a programból, de most inkább nyúljunk két jóval egyszerűbb, ámde egy ilyen megoldásnál fel sem merülő formulához, a MAX-hoz és a MIN-hez.
Például az elsőnél mondjuk meg, hogy január 15. és május 30.-a közötti intervallumból hány nap esik január elseje és április elseje közé. Finom kis fejtörő, főleg ha tudjuk, hogy alig néhány percünk van rá - de ha megvan a logika, akkor villámgyorsan összedobhatjuk az eredményt. És ahogy Excelben általában mindig, most sem egyetlen megoldás létezik, a kérdésre a választ ugyanis kis eltökéltséggel még egy IF-fel is ki tudjuk csikarni a programból, de most inkább nyúljunk két jóval egyszerűbb, ámde egy ilyen megoldásnál fel sem merülő formulához, a MAX-hoz és a MIN-hez.
A MAX nevéből adódóan megadja, hogy egy adott tömbben melyik a legnagyobb érték, a MIN pedig értelemszerűen a legkisebbet fogja visszaadni, ami nekünk itt azért fog jól jönni, mert meg fogjuk tudni, hogy a két összehasonlítandó intervallum kezdő illetve záró időpontjai közül melyik a nagyobb és a kisebb, azaz végül lesz majd két dátumunk, ahonnan már könnyen eljuthatunk a megoldáshoz.
Elsőként tehát nézzük meg, hogy első összehasonlításunknál melyik záródátum a kisebb a két pár közül, azaz:
=MIN(B$4,$F5)
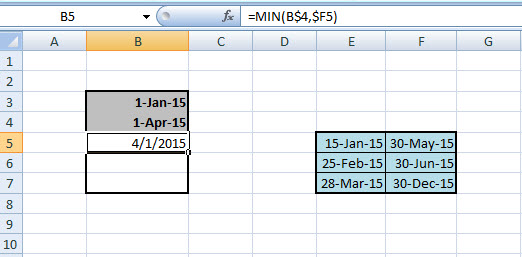 Innen pedig már tudni fogjuk, hogy április elseje a kisebbik záródátum. Ezután ki kell derítenünk, hogy melyik a nagyobb nyitódátum, ehhez jön majd segítségként a MAX, azaz:
Innen pedig már tudni fogjuk, hogy április elseje a kisebbik záródátum. Ezután ki kell derítenünk, hogy melyik a nagyobb nyitódátum, ehhez jön majd segítségként a MAX, azaz:
=MAX(B$3,$E5)
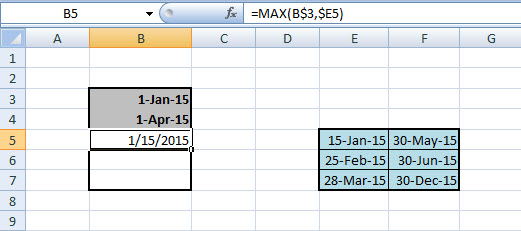 Innen pedig tudni fogjuk, hogy a nagyobb kezdődátum a január 15.-e, azaz ha ezt a két függvényt összedolgozzuk, akkor meg is van a közös intervallum, azaz a megoldás is. Na igen ám, de hogyan tegyük ezt?
Innen pedig tudni fogjuk, hogy a nagyobb kezdődátum a január 15.-e, azaz ha ezt a két függvényt összedolgozzuk, akkor meg is van a közös intervallum, azaz a megoldás is. Na igen ám, de hogyan tegyük ezt?
Ha szimplán ezt véssük be a cellánkba:
=MIN(B$4,$F5)-MAX(B$3,$E5)
akkor kapunk már egy számot, de ez még nem helyes, hiszen nem lesz benne maga a kiinduló- illetve záródátum, ezért egyet mindenképpen hozzá kell majd adnunk.
=MIN(B$4,$F5)-MAX(B$3,$E5)+1
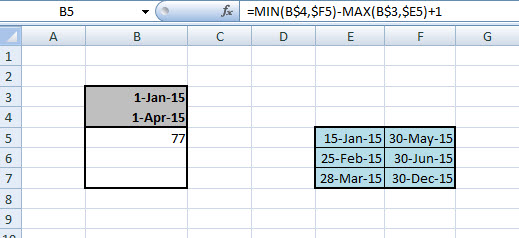 És ezzel kész is vagyunk, ott van az elvárt eredményünk. De módosítsunk egy kicsit a feladványon és tegyük fel, hogy olyan intervallumunk van az E5:F5-ben, amelynek nincs átfedése a kérdéses intervallumunkkal, lásd a példán:
És ezzel kész is vagyunk, ott van az elvárt eredményünk. De módosítsunk egy kicsit a feladványon és tegyük fel, hogy olyan intervallumunk van az E5:F5-ben, amelynek nincs átfedése a kérdéses intervallumunkkal, lásd a példán:
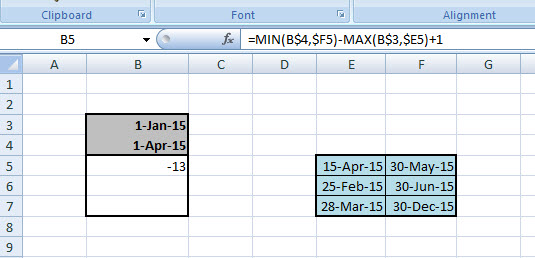 Ekkor az eredmény negatív szám lesz, ami nem értelmezhető, hiszen ilyenkor azt szeretnénk látni, hogy 0, azaz nincs átfedés - ismét egy feladat, amelyet másképp is meg tudnánk oldani, de térjünk csak vissza a MAX függvényre megint! A MAX ugyebár számokat, egy tömb értékeit hasonlítja össze és adja vissza nekünk a legnagyobbat, ergó ha a fenti eredményünket beépítjük egy MAX függvénybe, mint paraméter, majd felkínáljuk neki másik paraméterként a 0-t, akkor értelemszerűen a nulla nagyobb szám, mint a negatív szám, azaz mindig 0-t kapunk, ha nincs átfedés:
Ekkor az eredmény negatív szám lesz, ami nem értelmezhető, hiszen ilyenkor azt szeretnénk látni, hogy 0, azaz nincs átfedés - ismét egy feladat, amelyet másképp is meg tudnánk oldani, de térjünk csak vissza a MAX függvényre megint! A MAX ugyebár számokat, egy tömb értékeit hasonlítja össze és adja vissza nekünk a legnagyobbat, ergó ha a fenti eredményünket beépítjük egy MAX függvénybe, mint paraméter, majd felkínáljuk neki másik paraméterként a 0-t, akkor értelemszerűen a nulla nagyobb szám, mint a negatív szám, azaz mindig 0-t kapunk, ha nincs átfedés:
=MAX(0,MIN(B$4,$F5)-MAX(B$3,$E5)+1)
Sőt, ha a 0-t be sem írjuk, az Excel automatikusan nullához fogja hasonlítani a különbségünket, azaz ez lehet a végső megoldás:
=MAX(,MIN(B$4,$F5)-MAX(B$3,$E5)+1)
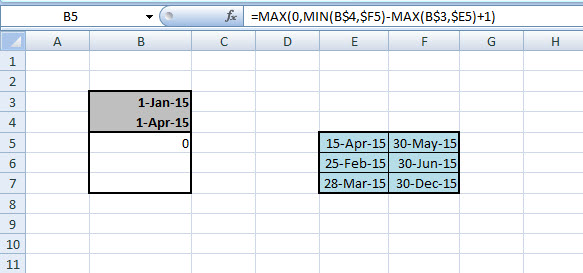 De ez tipikusan az a probléma, amire szerintem bőven több, mint egy megoldás létezhet, azaz bátran írjatok, ha van egy jóval egyszerűbb, vagányabb ötletetek!
De ez tipikusan az a probléma, amire szerintem bőven több, mint egy megoldás létezhet, azaz bátran írjatok, ha van egy jóval egyszerűbb, vagányabb ötletetek!
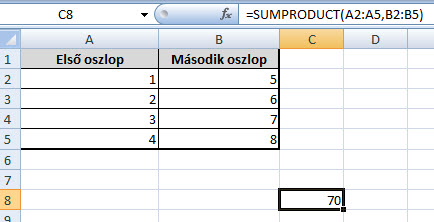 Mi van akkor, ha kicsit komplikálom az előbbi példát, és az első oszlopban most már nem számok, hanem mondjuk megyék fognak szerepelni (mondjuk ahol egy cég boltjai működnek) és azt szeretném megtudni, hogy mondjuk Csongrád megyében pontosan az adott bolt mekkora forgalmat generált egy adott periódus alatt. Még jómagam is egyértelműen az egyszerűbbnek tűnő, jobban ismert SUMIF megoldás mellett tenném le a voksot, de ne adjuk fel, tartsunk még ki a SUMPRODUCT mellett, hogy meglássuk valódi értékét!
Mi van akkor, ha kicsit komplikálom az előbbi példát, és az első oszlopban most már nem számok, hanem mondjuk megyék fognak szerepelni (mondjuk ahol egy cég boltjai működnek) és azt szeretném megtudni, hogy mondjuk Csongrád megyében pontosan az adott bolt mekkora forgalmat generált egy adott periódus alatt. Még jómagam is egyértelműen az egyszerűbbnek tűnő, jobban ismert SUMIF megoldás mellett tenném le a voksot, de ne adjuk fel, tartsunk még ki a SUMPRODUCT mellett, hogy meglássuk valódi értékét!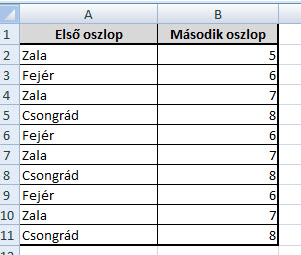
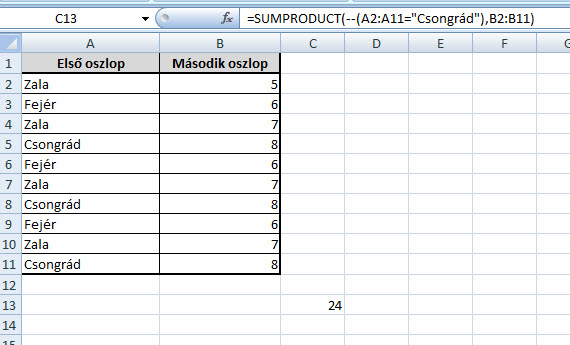 Hiszen első körben azért nem működött jól a formula, mert ugyan megtalálta a Csongrád értékeket, de ott a cella TRUE értéket vett fel, azzal pedig hiába szorozgatta a nyolcasainkat - a két kötőjellel viszont meg is van a kívánt eredményünk.
Hiszen első körben azért nem működött jól a formula, mert ugyan megtalálta a Csongrád értékeket, de ott a cella TRUE értéket vett fel, azzal pedig hiába szorozgatta a nyolcasainkat - a két kötőjellel viszont meg is van a kívánt eredményünk.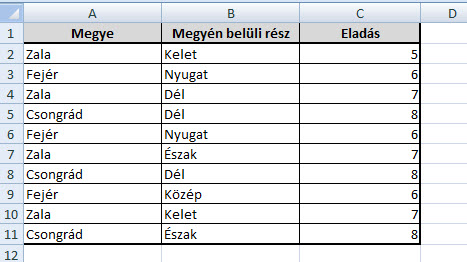
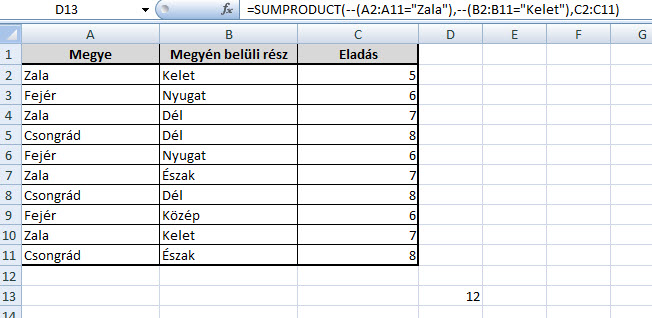 És done! Mintha egy negyven oszlopból álló listában filterezgetnénk oszloponként, hogy megkapjuk a vágyott szummát, csak ezt most belevághatjuk egyetlen függvénybe - nem mondom, hogy gyorsabb, de hogy szép megoldás, az biztos. Barátkozzunk egy kicsit most ezzel a függvénnyel, ugyanis még vissza fogok térni rá egy emeltszintű "SUMPRODUCT kiképzés" alkalmával.
És done! Mintha egy negyven oszlopból álló listában filterezgetnénk oszloponként, hogy megkapjuk a vágyott szummát, csak ezt most belevághatjuk egyetlen függvénybe - nem mondom, hogy gyorsabb, de hogy szép megoldás, az biztos. Barátkozzunk egy kicsit most ezzel a függvénnyel, ugyanis még vissza fogok térni rá egy emeltszintű "SUMPRODUCT kiképzés" alkalmával.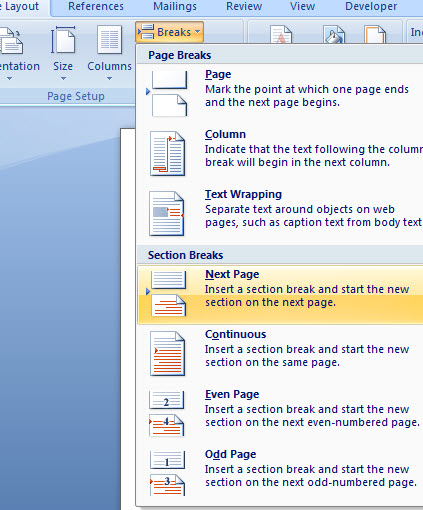 Ezután duplán kattintunk annak az oldalnak a Footerén, amelyből ki akarjuk szedni a számunkat, majd az itt megjelenő Same as Previous opcióra kattintunk, utána pedig Ribbonunk Design fülén a Navigation szekcióban kikapcsoljuk a Link to Previous szabályt, majd szabadon törölhetjük sorszámunkat a sorozatból az adott oldalon.
Ezután duplán kattintunk annak az oldalnak a Footerén, amelyből ki akarjuk szedni a számunkat, majd az itt megjelenő Same as Previous opcióra kattintunk, utána pedig Ribbonunk Design fülén a Navigation szekcióban kikapcsoljuk a Link to Previous szabályt, majd szabadon törölhetjük sorszámunkat a sorozatból az adott oldalon.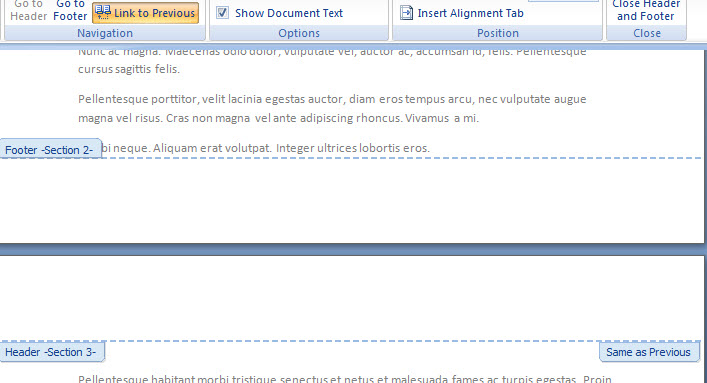
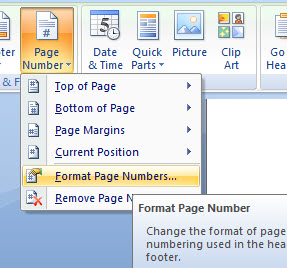
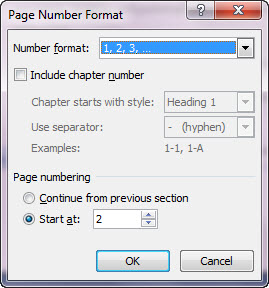 4. Innen pedig már nagyjából ugyanaz lesz a tennivaló, amit már fentebb részleteztem tapasztalataim kapcsán, azaz most annak az oldalnak az elejére kattintunk, amelyik a számozatlan lapunk lesz, majd a Page Layout ribbonfül Page Setup szekciójában a Break funkcióra kattintunk és beszúrunk egy Next Page breaket.
4. Innen pedig már nagyjából ugyanaz lesz a tennivaló, amit már fentebb részleteztem tapasztalataim kapcsán, azaz most annak az oldalnak az elejére kattintunk, amelyik a számozatlan lapunk lesz, majd a Page Layout ribbonfül Page Setup szekciójában a Break funkcióra kattintunk és beszúrunk egy Next Page breaket.
 Sok-sok kalkulációtól meg tudjuk magunkat kímélni, ha felírjuk elménk füzetének egyik lapjára a CONVERT formula nevét, ugyanis ennek segítségével 49 különböző mértékegység között tudunk átváltásokat végezni, persze csak egy bizonyos típuson belül (tehát kilométert ne akarjunk literre váltani). Be nem fogom most másolni ide az összes lehetőséget, aki szeretne elmélyülni a dologban, az hívja segítségül a Helpet a teljes listához.
Sok-sok kalkulációtól meg tudjuk magunkat kímélni, ha felírjuk elménk füzetének egyik lapjára a CONVERT formula nevét, ugyanis ennek segítségével 49 különböző mértékegység között tudunk átváltásokat végezni, persze csak egy bizonyos típuson belül (tehát kilométert ne akarjunk literre váltani). Be nem fogom most másolni ide az összes lehetőséget, aki szeretne elmélyülni a dologban, az hívja segítségül a Helpet a teljes listához.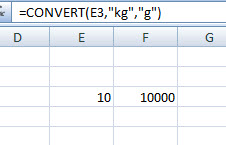 Mindenesetre példánkban az =CONVERT(E3,"kg","g") értelemszerűen ki fogja írni, hogy az E3 cellában tárolt 10 kilogramm pontosan hány grammnak felel meg.
Mindenesetre példánkban az =CONVERT(E3,"kg","g") értelemszerűen ki fogja írni, hogy az E3 cellában tárolt 10 kilogramm pontosan hány grammnak felel meg.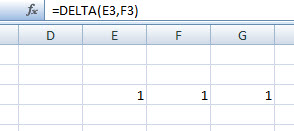 Könnyedén megkerülhető, ám szerintem elég szép megoldás az ERROR.TYPE függvény alkalmazása, amely konkrétan egy cellában lévő ERROR értékekből (pl. #NULL! vagy #VALUE!) számokat ad nekünk vissza, tehát mondjuk #NULL! esetén az ERROR.TYPE egy egyest fog nekünk kiírni. Ez akkor jöhet igazán jól, ha hibaüzenetek esetén inkább szöveget szeretnénk megjeleníteni, nem a megszokott és idegesítő #N/A-kat. Lásd példa.
Könnyedén megkerülhető, ám szerintem elég szép megoldás az ERROR.TYPE függvény alkalmazása, amely konkrétan egy cellában lévő ERROR értékekből (pl. #NULL! vagy #VALUE!) számokat ad nekünk vissza, tehát mondjuk #NULL! esetén az ERROR.TYPE egy egyest fog nekünk kiírni. Ez akkor jöhet igazán jól, ha hibaüzenetek esetén inkább szöveget szeretnénk megjeleníteni, nem a megszokott és idegesítő #N/A-kat. Lásd példa.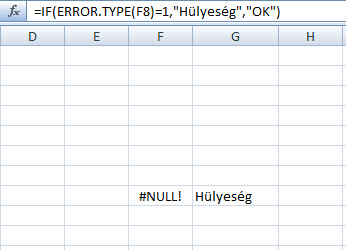
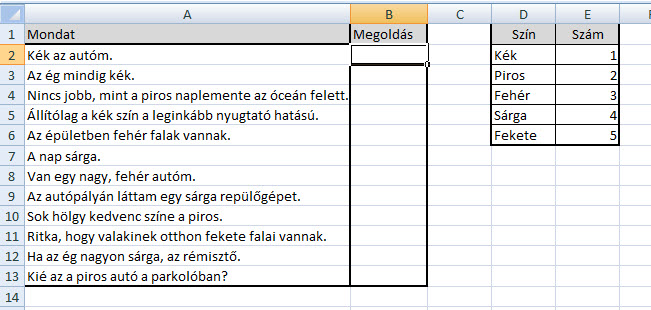 Már a példa felvázolása is utal arra, hogy itt valamiféle VLOOKUP-jellegű megoldást kell keresni, és ebben nincs is nagy tévedés, hiszen a megoldást a (nem is annyira) nagyszerű LOOKUP rejti magában, amelynek használata nem meglepő módon eléggé visszaszorult, hiszen a VLOOKUP jelentősen egyszerűbb és könnyebb használatot tesz lehetővé.
Már a példa felvázolása is utal arra, hogy itt valamiféle VLOOKUP-jellegű megoldást kell keresni, és ebben nincs is nagy tévedés, hiszen a megoldást a (nem is annyira) nagyszerű LOOKUP rejti magában, amelynek használata nem meglepő módon eléggé visszaszorult, hiszen a VLOOKUP jelentősen egyszerűbb és könnyebb használatot tesz lehetővé.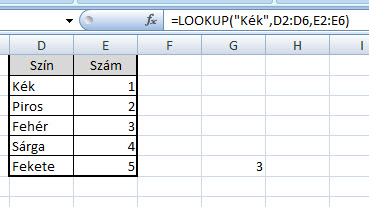
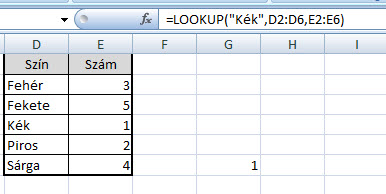 Na de ugorjunk vissza a kiinduló problémához. A LOOKUP formulával tehát nagyjából megbarátkoztunk, de lehet, hogy sokaknak még nem áll össze, hogy ez pontosan hogy is fog segíteni nekünk, ami érthető is, ugyanis még van egy másik függvény is, amit majd a LOOKUP-ba kell ágyaznunk, ez pedig igencsak szorgos és hasznos kis barátunk, a SEARCH. Szerintem nem nagyon van Excelt rendszeresen használó ember, aki ezt ne ismerné, hiszen kis formulánk az első paramétereként megadott szót/szövegrészt fog egy, a második paramétereként megadott szövegben keresni és visszaadja, hogy hányadik karakternél kezdődik keresett szövegünk.
Na de ugorjunk vissza a kiinduló problémához. A LOOKUP formulával tehát nagyjából megbarátkoztunk, de lehet, hogy sokaknak még nem áll össze, hogy ez pontosan hogy is fog segíteni nekünk, ami érthető is, ugyanis még van egy másik függvény is, amit majd a LOOKUP-ba kell ágyaznunk, ez pedig igencsak szorgos és hasznos kis barátunk, a SEARCH. Szerintem nem nagyon van Excelt rendszeresen használó ember, aki ezt ne ismerné, hiszen kis formulánk az első paramétereként megadott szót/szövegrészt fog egy, a második paramétereként megadott szövegben keresni és visszaadja, hogy hányadik karakternél kezdődik keresett szövegünk.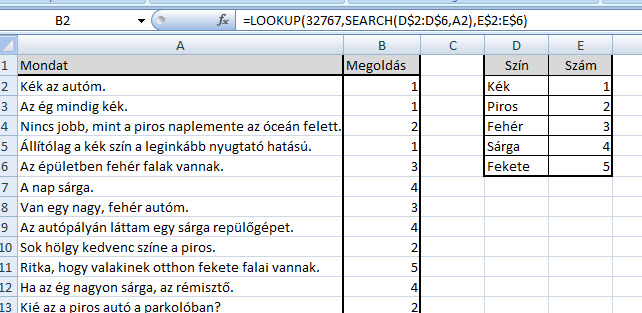
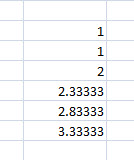 Hogy ne csak egyetlen problémán lássuk ezt a történetet, íme egy másik hasonló kérdés, azaz ha a következő képen látható sorozatot eggyel lejjebb húzzuk, miért 47 lesz a következő érték?
Hogy ne csak egyetlen problémán lássuk ezt a történetet, íme egy másik hasonló kérdés, azaz ha a következő képen látható sorozatot eggyel lejjebb húzzuk, miért 47 lesz a következő érték?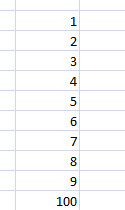 Hivatalosan dokumentált magyarázatról nem tudok, de az én elméletem szerint a magyarázat a lineáris regresszióban és a trendvonalban keresendő, azaz ha felrajzoljuk értékeinket egy koordinátarendszerben és megpróbáljuk összehozni az úgynevezett "best-fit" lineáris trendvonalat, akkor az Excel számítása szerint a koordinátarendszerben a trendnek megfelelő következő érték az Autofill által generált szám lenne.
Hivatalosan dokumentált magyarázatról nem tudok, de az én elméletem szerint a magyarázat a lineáris regresszióban és a trendvonalban keresendő, azaz ha felrajzoljuk értékeinket egy koordinátarendszerben és megpróbáljuk összehozni az úgynevezett "best-fit" lineáris trendvonalat, akkor az Excel számítása szerint a koordinátarendszerben a trendnek megfelelő következő érték az Autofill által generált szám lenne.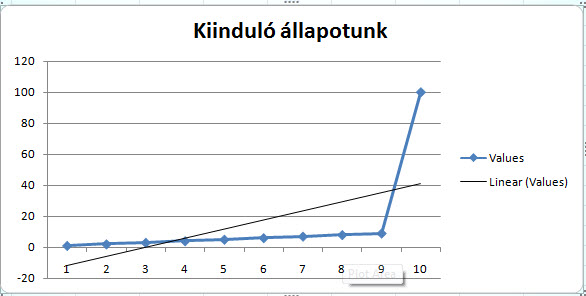 Az első diagramunk a rajta lévő trendvonallal tökéletesen mutatja a lineáris trendjét számaink alakulásának - ha ezt a trendvonalat továbbhúznánk, a következő elem a 47 lenne, ahogy ez a második diagramon tökéletesen látszik is. És ez az elmélet működik az 1,1,2-es sorozatunkra is, sőt igazából bármely olyan nem lineáris sorozatra, amelynél Autofillt szeretnénk használni.
Az első diagramunk a rajta lévő trendvonallal tökéletesen mutatja a lineáris trendjét számaink alakulásának - ha ezt a trendvonalat továbbhúznánk, a következő elem a 47 lenne, ahogy ez a második diagramon tökéletesen látszik is. És ez az elmélet működik az 1,1,2-es sorozatunkra is, sőt igazából bármely olyan nem lineáris sorozatra, amelynél Autofillt szeretnénk használni.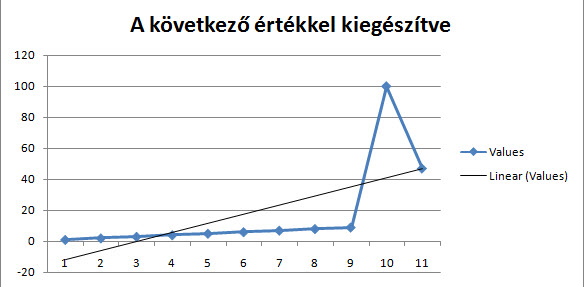 Persze ez csak inkább elméleti kihívás volt, hiszen ha konkrétan tudjuk, hogy mit szeretnénk látni következő értékként az Autofill által felkínált verzió helyett, az nem lehet túlságosan nagy feladat, hiszen mondjuk a CTRL billentyű használatával az Autofillünket másolásra kényszeríthetjük, de mondjuk a következő példa esetén is könnyen elérhetjük az eredményünket függvények segítségével.
Persze ez csak inkább elméleti kihívás volt, hiszen ha konkrétan tudjuk, hogy mit szeretnénk látni következő értékként az Autofill által felkínált verzió helyett, az nem lehet túlságosan nagy feladat, hiszen mondjuk a CTRL billentyű használatával az Autofillünket másolásra kényszeríthetjük, de mondjuk a következő példa esetén is könnyen elérhetjük az eredményünket függvények segítségével. Több megoldás is létezik, de én elsőre valószínűleg egy IF - COUNTIF kombinációt használnék. A COUNTIF-ről tudjuk, hogy egy adott tartományon belül számolja meg a második paramétereként megadott kritériumnak megfelelő értékeket, azaz példánk esetén a
Több megoldás is létezik, de én elsőre valószínűleg egy IF - COUNTIF kombinációt használnék. A COUNTIF-ről tudjuk, hogy egy adott tartományon belül számolja meg a második paramétereként megadott kritériumnak megfelelő értékeket, azaz példánk esetén a Tehát az előbb már megismert COUNTIF-fel megszámoljuk F1 előfordulását, majd megnézzük, hogy ez egyenlő-e hárommal vagy sem. Amennyiben egyenlő hárommal, akkor a következő cellába az F1 értékét eggyel megnövelve írja, ha nem egyenlő hárommal, akkor még F1 értékét írja ki. Hát, én az ilyenek miatt imádom az Excelt (is).
Tehát az előbb már megismert COUNTIF-fel megszámoljuk F1 előfordulását, majd megnézzük, hogy ez egyenlő-e hárommal vagy sem. Amennyiben egyenlő hárommal, akkor a következő cellába az F1 értékét eggyel megnövelve írja, ha nem egyenlő hárommal, akkor még F1 értékét írja ki. Hát, én az ilyenek miatt imádom az Excelt (is).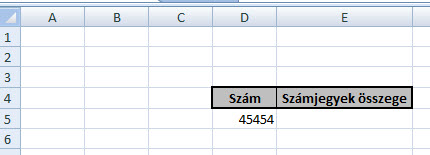 Ahogy a legtöbb ilyen problémánál, a kulcs ismét a logika megtalálása, hiszen utána azt képletekbe varázsolni már nem túlságosan nagy kunszt, jelen esetben pedig ez a logika igazából egy nagyon fontos Excel-függvényen alapul, ami nem más, mint az OFFSET. Ez a formula egy, az általunk paraméterként megadott magasságú, szélességű hivatkozást fog visszaadni nekünk egy cellától vagy cellatartománytól meghatározott sornyi és oszlopnyi távolságra. Ez most talán töményre sikeredett, de lássuk inkább egy példán:
Ahogy a legtöbb ilyen problémánál, a kulcs ismét a logika megtalálása, hiszen utána azt képletekbe varázsolni már nem túlságosan nagy kunszt, jelen esetben pedig ez a logika igazából egy nagyon fontos Excel-függvényen alapul, ami nem más, mint az OFFSET. Ez a formula egy, az általunk paraméterként megadott magasságú, szélességű hivatkozást fog visszaadni nekünk egy cellától vagy cellatartománytól meghatározott sornyi és oszlopnyi távolságra. Ez most talán töményre sikeredett, de lássuk inkább egy példán: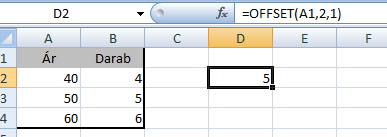 Ez az egyszerű kis OFFSET az A1-es cellától fog majd két sort lefelé haladni, majd utána jobbra egy oszlopot (használhatnánk negatív számokat is persze a másik irányhoz) és kiírja az ott lévő értéket. Ez hogy fog jól jönni majd a megoldásunkhoz? Nos, a célunk az, hogy szerezzünk egy olyan tartományra való hivatkozást, amely a célszámunk számjegyei számának megfelelő függőleges tartományra mutat, tehát ha a példánkban lévő öt számjegyből álló számot vizsgáljuk, akkor egy öt soros tartományt szeretnénk összehozni - igen, mert függőlegesen már pár lépés után szépen össze fogjuk majd tudni adni az értékeket.
Ez az egyszerű kis OFFSET az A1-es cellától fog majd két sort lefelé haladni, majd utána jobbra egy oszlopot (használhatnánk negatív számokat is persze a másik irányhoz) és kiírja az ott lévő értéket. Ez hogy fog jól jönni majd a megoldásunkhoz? Nos, a célunk az, hogy szerezzünk egy olyan tartományra való hivatkozást, amely a célszámunk számjegyei számának megfelelő függőleges tartományra mutat, tehát ha a példánkban lévő öt számjegyből álló számot vizsgáljuk, akkor egy öt soros tartományt szeretnénk összehozni - igen, mert függőlegesen már pár lépés után szépen össze fogjuk majd tudni adni az értékeket.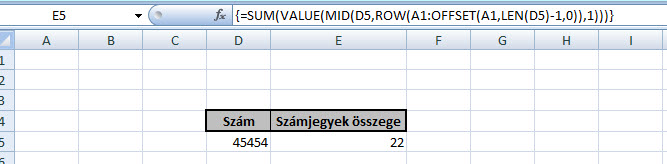 Ugye, hogy végigvezetve nem is annyira földtől elrugaszkodott ez a feladat sem? Persze feltételezve, hogy többen már ismerték ezt a feladványt vagy nem okozott nekik gondot a megoldás, álljon itt egy kis kiegészítő kérdés: mit kellene még beiktatnunk, hogy számjegyeink szummájának számjegyeit is összegezzük és bármilyen hosszú szám esetén egyetlen számjegyet kapjunk a végén?
Ugye, hogy végigvezetve nem is annyira földtől elrugaszkodott ez a feladat sem? Persze feltételezve, hogy többen már ismerték ezt a feladványt vagy nem okozott nekik gondot a megoldás, álljon itt egy kis kiegészítő kérdés: mit kellene még beiktatnunk, hogy számjegyeink szummájának számjegyeit is összegezzük és bármilyen hosszú szám esetén egyetlen számjegyet kapjunk a végén?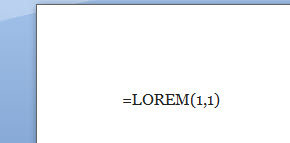 Majd nyomjuk egy ENTER-t és már előttünk is van egy teljesen értelmezhetetlen latin mondat. A LOREM funkció paraméterek nélkül is használható, de ha paraméterekkel használjuk, akkor az első szám a bekezdéseket, a második pedig a bekezdésekben szereplő mondatok számát jelenti, ergó
Majd nyomjuk egy ENTER-t és már előttünk is van egy teljesen értelmezhetetlen latin mondat. A LOREM funkció paraméterek nélkül is használható, de ha paraméterekkel használjuk, akkor az első szám a bekezdéseket, a második pedig a bekezdésekben szereplő mondatok számát jelenti, ergó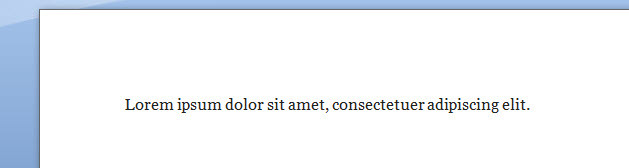 Ugyanezt tudják egyébként a =RAND(1,1) és a =RAND.OLD(1,1) funkciók is, annyi különbséggel, hogy mindkettőnél pár értelmes angol mondat ismétlődik, illetve utóbbi WORD 2003 vagy régebbi verziókkal is kompatibilis és használható. Hozzám valahogy a lorem ipsum áll közelebb, de az biztos, hogy a szövegszerkesztőt sokat használók számára mindegyik megoldás megjegyzendő.
Ugyanezt tudják egyébként a =RAND(1,1) és a =RAND.OLD(1,1) funkciók is, annyi különbséggel, hogy mindkettőnél pár értelmes angol mondat ismétlődik, illetve utóbbi WORD 2003 vagy régebbi verziókkal is kompatibilis és használható. Hozzám valahogy a lorem ipsum áll közelebb, de az biztos, hogy a szövegszerkesztőt sokat használók számára mindegyik megoldás megjegyzendő. Szóval van egy szövegünk, amelyből egy-két szövegrészt szeretnénk kiszedni (mondjuk egy leíráshoz ollózgatunk innen-onnan), akkor jelöljük ki az első fontos szövegrészünket, majd nyomjunk CTRL+F3-at. Ez kivágja a kijelölt szövegrészt, úgyhogy mehetünk is tovább, CTRL+F3-al szépen gyűjtögessük össze a nekünk fontos tartalmakat. Aztán ha megvagyunk, CTRL+SHIFT+F3 lenyomásával bárhova be is illeszthetjük az egészet egyben. Persze beillesztés előtt meg is nézhetjük az összemásolgatott szövegünket, ha a Ribbonunk Insert füle alatt található Quick Parts menüre kattintunk (TEXT szekció) és ott a Building Blocks Organizerbe lépünk. Itt Spike név alatt meg is találjuk, amit összemásolgattunk.
Szóval van egy szövegünk, amelyből egy-két szövegrészt szeretnénk kiszedni (mondjuk egy leíráshoz ollózgatunk innen-onnan), akkor jelöljük ki az első fontos szövegrészünket, majd nyomjunk CTRL+F3-at. Ez kivágja a kijelölt szövegrészt, úgyhogy mehetünk is tovább, CTRL+F3-al szépen gyűjtögessük össze a nekünk fontos tartalmakat. Aztán ha megvagyunk, CTRL+SHIFT+F3 lenyomásával bárhova be is illeszthetjük az egészet egyben. Persze beillesztés előtt meg is nézhetjük az összemásolgatott szövegünket, ha a Ribbonunk Insert füle alatt található Quick Parts menüre kattintunk (TEXT szekció) és ott a Building Blocks Organizerbe lépünk. Itt Spike név alatt meg is találjuk, amit összemásolgattunk.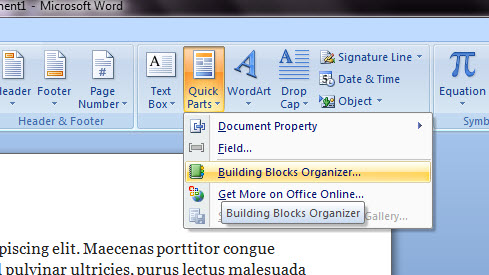 Ezzel a funkcióval sokan azért nem is akarnak barátkozni, mert alapesetben csak kivág és beilleszt, tehát pont a másolást nem tudja teljesíteni, amire igazán szükségünk lenne - nos, ez nem így van, egyszerűen a CTRL+F3 kombináció után CTRL+Z-vel vissza kell vonnunk az előző műveletet. Így a kivágott szövegünk visszakerül, ám a Spike blokkunkból már nem törlődik, szóval elérhető a másolás lehetősége is.
Ezzel a funkcióval sokan azért nem is akarnak barátkozni, mert alapesetben csak kivág és beilleszt, tehát pont a másolást nem tudja teljesíteni, amire igazán szükségünk lenne - nos, ez nem így van, egyszerűen a CTRL+F3 kombináció után CTRL+Z-vel vissza kell vonnunk az előző műveletet. Így a kivágott szövegünk visszakerül, ám a Spike blokkunkból már nem törlődik, szóval elérhető a másolás lehetősége is.
 Nem egy Excel, de arra a célra tökéletes, amire WORD használata közben szükségünk lehet.
Nem egy Excel, de arra a célra tökéletes, amire WORD használata közben szükségünk lehet.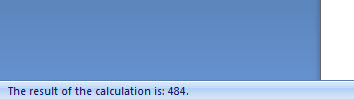
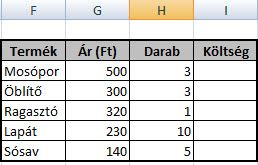 De mi lenne, ha tömbképlettel próbálkoznánk, hiszen ezek a képletek egyszerre több kalkulációt is el tudnak végezni és megspórolnának nekünk egy kis időt? Jelöljük ki a Költség oszlopot, I3-tól I7-ig, majd a Képlet (Formula) mezőbe írjuk be a következőt:
De mi lenne, ha tömbképlettel próbálkoznánk, hiszen ezek a képletek egyszerre több kalkulációt is el tudnak végezni és megspórolnának nekünk egy kis időt? Jelöljük ki a Költség oszlopot, I3-tól I7-ig, majd a Képlet (Formula) mezőbe írjuk be a következőt: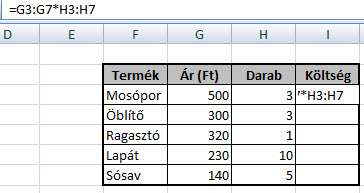
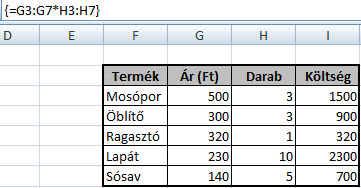 Anno a Microsoft úgy reklámozta ezeket a képleteket, hogy tömbképletekkel kalkulációs fájlunk mérete kisebb lesz és biztonságosabb is lesz a használata, hiszen nem lehet csak úgy egyszerűen megváltoztatni egy elemét a tömbképletünknek. Én azonban azt mondanám, hogy a legfontosabb érv mellettük az, hogy vannak olyan problémák, amelyeket "normál" módszerekkel, függvényekkel már nem lehet megoldani.
Anno a Microsoft úgy reklámozta ezeket a képleteket, hogy tömbképletekkel kalkulációs fájlunk mérete kisebb lesz és biztonságosabb is lesz a használata, hiszen nem lehet csak úgy egyszerűen megváltoztatni egy elemét a tömbképletünknek. Én azonban azt mondanám, hogy a legfontosabb érv mellettük az, hogy vannak olyan problémák, amelyeket "normál" módszerekkel, függvényekkel már nem lehet megoldani.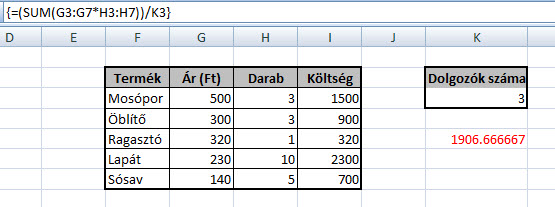 Ha ki szeretnénk számolni az egy dolgozóra jutó költség összegét, valószínűleg ismét csak képletezgetnénk egy egyenlőségjel után, ami persze érthető is, hiszen egy ilyen egyszerű probléma esetén ki a fene szórakozik tömbképletekkel, viszont a logikát megérteni jó lesz, hiszen ha egy tetszőleges cellába az alábbi képletet írjuk be és nyomunk utána CTRL+SHIFT+ENTER-t, nézzük csak mit kapunk:
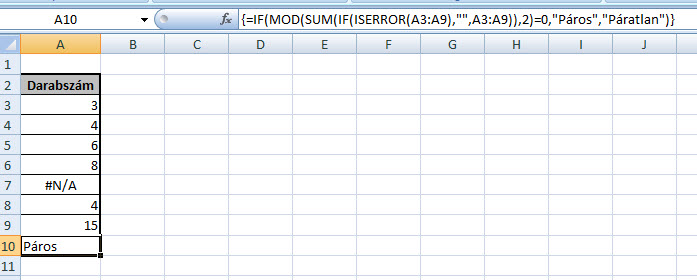
Ha ki szeretnénk számolni az egy dolgozóra jutó költség összegét, valószínűleg ismét csak képletezgetnénk egy egyenlőségjel után, ami persze érthető is, hiszen egy ilyen egyszerű probléma esetén ki a fene szórakozik tömbképletekkel, viszont a logikát megérteni jó lesz, hiszen ha egy tetszőleges cellába az alábbi képletet írjuk be és nyomunk utána CTRL+SHIFT+ENTER-t, nézzük csak mit kapunk: Ugye, hogy nem is olyan egyszerű? Az a fránya #N/A eléggé megakasztja a SUM működését, amit viszont a következő tömbképlettel könnyedén ki tudunk játszani:
Ugye, hogy nem is olyan egyszerű? Az a fránya #N/A eléggé megakasztja a SUM működését, amit viszont a következő tömbképlettel könnyedén ki tudunk játszani: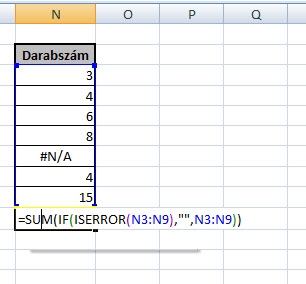 De hogy még ezt is megspékeljük egy kis elmélkednivalóval, legyen az a feladat, hogy még mindig a fenti táblánál maradva, egyetlen szót írassunk ki eredménycellánkba, mégpedig azt, hogy szummánk eredménye páros vagy páratlan szám-e. Ehhez a MOD függvényre lesz majd szükségünk, amely roppant egyszerű célt szolgál, a paraméterként beadott osztandó és osztó alapján kiírja nekünk az osztás műveletének maradékát - ergó ha ez a maradék nulla, páros számról beszélünk, ha nem, páratlanról. És ezt kellene még majd beágyaznunk a fenti tömbképletbe, hogy a végeredményünk tényleg csak egy szó legyen.
De hogy még ezt is megspékeljük egy kis elmélkednivalóval, legyen az a feladat, hogy még mindig a fenti táblánál maradva, egyetlen szót írassunk ki eredménycellánkba, mégpedig azt, hogy szummánk eredménye páros vagy páratlan szám-e. Ehhez a MOD függvényre lesz majd szükségünk, amely roppant egyszerű célt szolgál, a paraméterként beadott osztandó és osztó alapján kiírja nekünk az osztás műveletének maradékát - ergó ha ez a maradék nulla, páros számról beszélünk, ha nem, páratlanról. És ezt kellene még majd beágyaznunk a fenti tömbképletbe, hogy a végeredményünk tényleg csak egy szó legyen.