Az Excel függvényeinek magas szintű ismerete és biztos használata alapvető a függvények másik dimenziójának, a tömbfüggvényeknek a használatához - tudjuk, ezek a CTRL+SHIFT+ENTER segítségével előhívható és tömbök kezelésére szolgáló függvények. Ennek tükrében és főleg használatuk nehézkessége miatt nem igazán voltak elterjedtek, de ahogy az elmúlt hetek híreiből kiderült, nem is fognak nagyobb szintű ismertségre szert tenni a jövőben sem, ugyanis már itt vannak az előszobában az Excel beépített, dinamikus tömbfüggvényei. 2018. szeptemberében ugyanis a Microsoft bemutatott hét új függvényt, amelyek dinamikus tömbök kezelésére fognak szolgálni és ezzel feleslegessé teszik a régi CTRL+SHIFT+ENTER-féle tömbfüggvények használatát.
Jelenleg azok számára elérhető ez a hét funkció, akik feliratkoztak az Office 365 Insiders Programjára és bár hivatalos dátumot még nem tett közzé a cég, a közeljövőben minden felhasználó megismerkedhet ezekkel az új lehetőségeket jelentő függvényekkel és a velük együtt érkező új, ún. spill range lehetőségeivel. Hogy miről is van szó, azt a következő példán keresztül mutatom be. Adott a következő tábla, amely néhány várost tartalmaz, de több előfordulással:
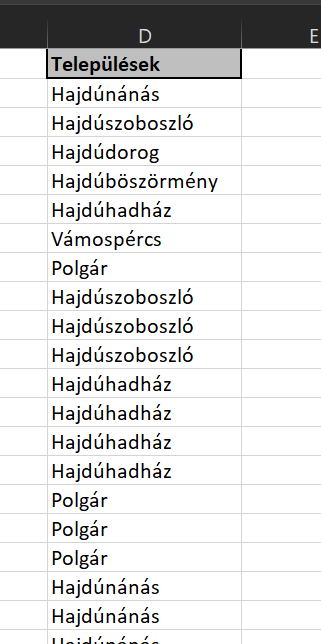 Alapesetben, ha azt szerettük volna megmondani, hogy melyek az egyedi értékek, akkor mindenféle függvényes machinációkat alkalmazhattunk vagy akár egy tömbfüggvényt, ahogy én fogom mindjárt tenni a jó öreg INDEX-MATCH baráti páros segítségével.
Alapesetben, ha azt szerettük volna megmondani, hogy melyek az egyedi értékek, akkor mindenféle függvényes machinációkat alkalmazhattunk vagy akár egy tömbfüggvényt, ahogy én fogom mindjárt tenni a jó öreg INDEX-MATCH baráti páros segítségével.
Azt már ugye betéve tudjuk, hogy az INDEX formulának a segítségével egy tábla megadott sorában, oszlopában vagy sor és oszlop kereszteződésében található értéket kaphatjuk vissza, a MATCH pedig az első paramétereként megadott érték helyzetét fogja a második paramétereként megadott tartományból megadni nekünk (a harmadik paraméter a pontos egyezés, kisebb-nagyobb feltétel megadására ad lehetőséget). Így a következő formula tömbfüggvényként használva segíteni fog nekünk az egyedi értékek meghatározásában:
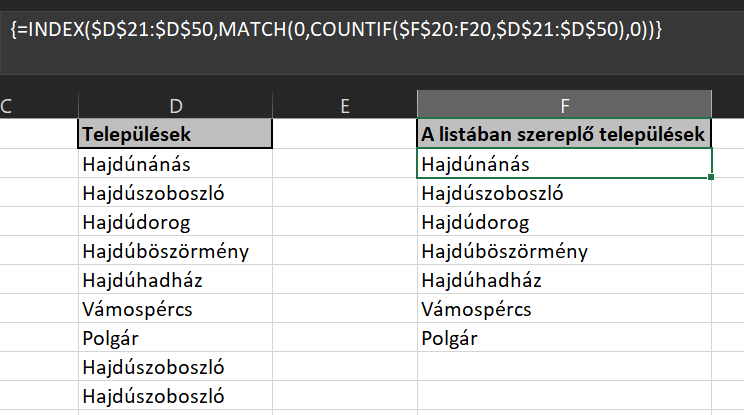
INDEX($D$21:$D$50,MATCH(0,COUNTIF($F$20:F20,$D$21:$D$50),0))
Az INDEX segítségével megadjuk, hogy a D21:D50-es tartományban keressük az értéket és hogy hányadik sorban van ez az érték (ugye ez az INDEX második, sorra vonatkozó paramétere), azt a MATCH adja meg. De a MATCH sem olyan simán fogja ezt visszaadni, ugyanis a használt tömbhöz beágyazunk egy COUNTIF-et, ami a céltáblánkat fogja vizsgálni soronként és azt nézi meg, hogy beírtuk-e már a céltáblánkba az adott várost, mert ha be, akkor ugyebár a MATCH nem nullát fog találni (hiszen 0-t keresünk) és megy a következő sorra a függvény. Ha viszont nem találja az adott várost, akkor beírja a következő sorba, majd megy tovább a kiinduló tartományunkon és vizsgálja a következő értéket.
Ezt így magyarázatként leírni elég körülményes volt, bár remélhetőleg maga a függvény annyira nem komplikált - a lényeg tehát, hogy erre nyomtunk egy CTRL+SHIFT+ENTER-t és automatikus kitöltés után már látjuk is az eredményünk:
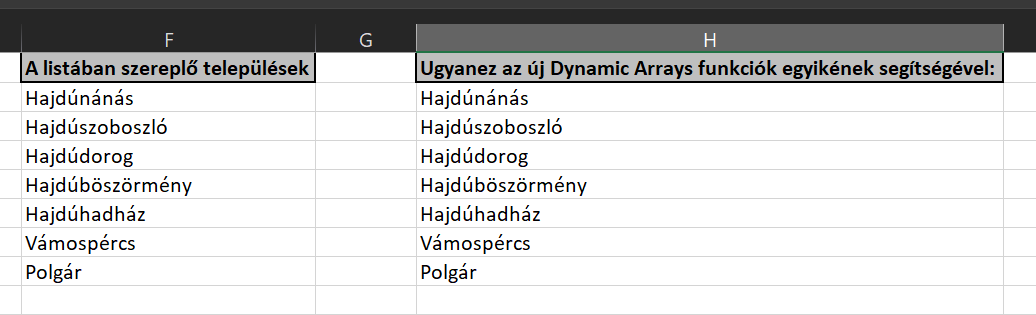
 Na viszont, amint elérhető lesz mindenki számára a dinamikus tömbök funkcionalitása, akkor az egész egyetlen könnyű lépésből végrehajtható lesz. Ugyanis szimplán csak beírjuk a funkció nevét (UNIQUE ebben az esetben), majd az eredményeket azonnal látni is fogjuk - tehát azonnal ki is tölti a céltáblát az összes egyedi értékkel.
Na viszont, amint elérhető lesz mindenki számára a dinamikus tömbök funkcionalitása, akkor az egész egyetlen könnyű lépésből végrehajtható lesz. Ugyanis szimplán csak beírjuk a funkció nevét (UNIQUE ebben az esetben), majd az eredményeket azonnal látni is fogjuk - tehát azonnal ki is tölti a céltáblát az összes egyedi értékkel.
 És ez a funkció még paraméterezhető is, tehát megadhatjuk azt is, hogy csak azokat az értékeket akarjuk visszakapni, amelyek pontosan egyszer fordulnak elő, de akár több oszlopból álló tartományok vizsgálatára is lesz lehetőség. És ez még csak egy, az ígért hét új funkció közül, úgyhogy érdemes a "spill range" fogalmával is megbarátkoznunk gyorsan. A Spill Range az a tartomány, ahova vissza fogja adni a dinamikus tömbfüggvény az eredményt, tehát nincs már több CTRL+SHIFT+ENTER és automatikus kitöltés.
És ez a funkció még paraméterezhető is, tehát megadhatjuk azt is, hogy csak azokat az értékeket akarjuk visszakapni, amelyek pontosan egyszer fordulnak elő, de akár több oszlopból álló tartományok vizsgálatára is lesz lehetőség. És ez még csak egy, az ígért hét új funkció közül, úgyhogy érdemes a "spill range" fogalmával is megbarátkoznunk gyorsan. A Spill Range az a tartomány, ahova vissza fogja adni a dinamikus tömbfüggvény az eredményt, tehát nincs már több CTRL+SHIFT+ENTER és automatikus kitöltés.
Ha a Spill Rangeben vannak nem üres cellák is, akkor hibaüzenetet kapunk és a funkció lehetőséget ad azon cellák elmozgatására, majd automatikusan folytatja/megcsinálja a kitöltést.
És akkor ismerkedhetünk további új lehetőségekkel is, mint például a spill hivatkozással, amely mondjuk így nézne ki a példánk esetében:
A2#
Ha ezt adjuk meg egy függvényben, akkor az egész spill tartományra fogunk hivatkozni, amelynek első cellája az A2, tehát simán összedolgozhatunk több dinamikus tömbfüggvényt is.
És hogy jelenleg melyik 7 új funkciót tesztelhetik a szerencsések és melyekre várhat az egész Excel-társadalom?
UNIQUE - erről volt szó fentebb
FILTER - a megadott paramétereink mentén szűrhetünk le egy adatbázisban és automatikusan visszakapjuk a szűrés eredményét
RANDARRAY - kitölt nekünk egy tartományt véletlenszerűen generált számokkal (tehát nincs már RANDBETWEEN és automatikus kitöltéssel küszködés)
SINGLE - visszaad egy értéket egy cella sorának/oszlopának kereszteződéséből
SORT - sortolni tudunk egy megadott tartományt
SORTBY - sortolni tudunk egy megadott tartományt egy másik tartomány értékei alapján
SEQUENCE - egymást szekvenciálisan követő számokból tudunk tartományt létrehozni
És ami a legjobb, hogy ezek ugyan új funkcióként jönnek, de a funkcionalitás kiterjesztett a régi funkciókra is, tehát a spill range innentől kezdve napi szinten életünk része lesz. Őszintén mondom, alig várom!
 Tehát ha lenne rajta megosztás, azt le tudnánk venni róla, de valamiért nincs rá lehetőségünk, hogy megosszuk a fájlunkat. Mielőtt a miértre kitérnénk, álljon itt egy megoldási javaslat. Kattintsunk jobb egérgombbal a ribbonon, majd a felugró context menüből válasszuk ki a Customize the Ribbon menüpontot:
Tehát ha lenne rajta megosztás, azt le tudnánk venni róla, de valamiért nincs rá lehetőségünk, hogy megosszuk a fájlunkat. Mielőtt a miértre kitérnénk, álljon itt egy megoldási javaslat. Kattintsunk jobb egérgombbal a ribbonon, majd a felugró context menüből válasszuk ki a Customize the Ribbon menüpontot: A Choose commands legördülő menüből válasszuk ki az All Commands lehetőséget, majd görgessünk le a Share Workbook (Legacy) parancshoz, majd Addel adjuk hozzá a ribbonunkhoz. Fontos, hogy már meglévő csoportba nem tudjuk betenni ezt az új parancsot, ezért létre kell hoznunk egy új Custom Groupot a New Group lenyomásával.
A Choose commands legördülő menüből válasszuk ki az All Commands lehetőséget, majd görgessünk le a Share Workbook (Legacy) parancshoz, majd Addel adjuk hozzá a ribbonunkhoz. Fontos, hogy már meglévő csoportba nem tudjuk betenni ezt az új parancsot, ezért létre kell hoznunk egy új Custom Groupot a New Group lenyomásával. A hozzáadás után pedig szépen meg is jelent a Review ribbonfül alatt az új parancs, amit már úgy tudunk használni, ahogy korábban is megszoktuk a megosztási lehetőséget.
A hozzáadás után pedig szépen meg is jelent a Review ribbonfül alatt az új parancs, amit már úgy tudunk használni, ahogy korábban is megszoktuk a megosztási lehetőséget.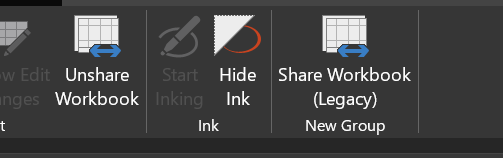 A miértre a válasz pedig igazából egy új funkcióban rejlik, méghozzá a co-authoring lehetőségben, ami a legújabb Excel-verzióban már megváltoztatta a korábbi megosztási opciókat, így Shared workbook már nem létezik abban a formában mint korábban. Tehát az, hogy nem találjuk a Share Workbook gombot a helyén, szándékos, helyette ugyanis a jobb felső sarokban lévő Share gomb lenyomásával és e-mail címek megadásával már a felhőben tudunk egyszerre dolgozni ugyanazon a munkafüzeten - követve egyébként a tech világban jelenleg vezető irányt, a felhő alapú munkát.
A miértre a válasz pedig igazából egy új funkcióban rejlik, méghozzá a co-authoring lehetőségben, ami a legújabb Excel-verzióban már megváltoztatta a korábbi megosztási opciókat, így Shared workbook már nem létezik abban a formában mint korábban. Tehát az, hogy nem találjuk a Share Workbook gombot a helyén, szándékos, helyette ugyanis a jobb felső sarokban lévő Share gomb lenyomásával és e-mail címek megadásával már a felhőben tudunk egyszerre dolgozni ugyanazon a munkafüzeten - követve egyébként a tech világban jelenleg vezető irányt, a felhő alapú munkát.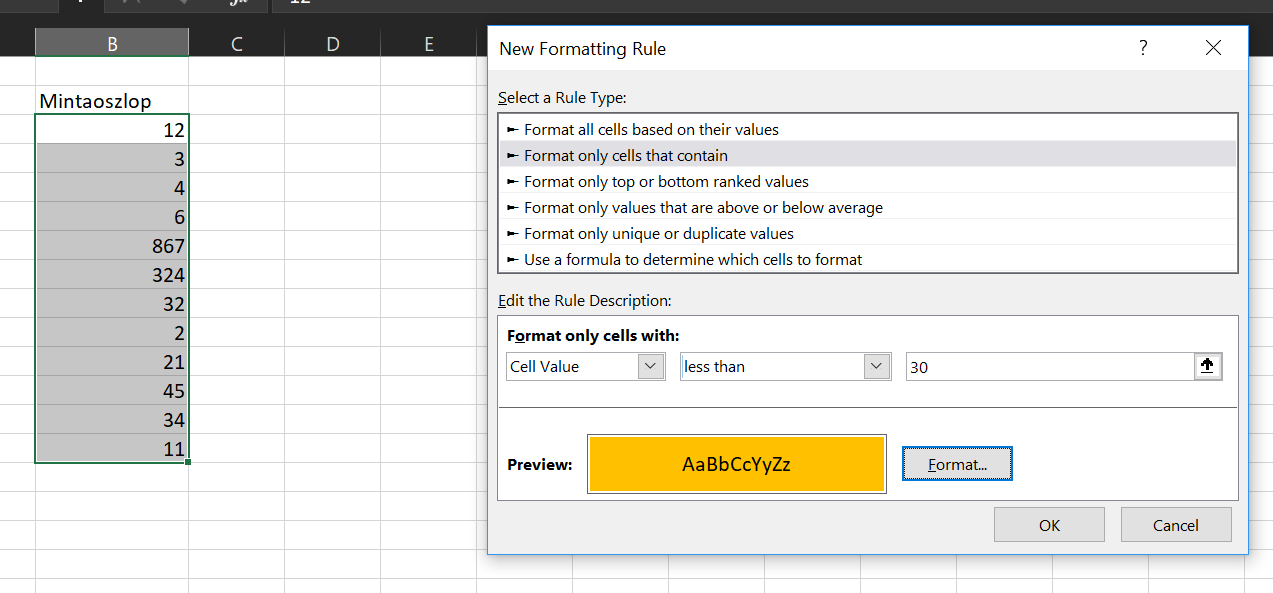 Ahogy látható, azt szeretném elérni, hogy minden olyan cellám háttere sárga legyen, ahol az érték harmincnál kevesebb. Vegyük észre, hogy ki van jelölve a tartományom B3-tól B14-ig, tehát csak erre fog vonatkozni a formázás.
Ahogy látható, azt szeretném elérni, hogy minden olyan cellám háttere sárga legyen, ahol az érték harmincnál kevesebb. Vegyük észre, hogy ki van jelölve a tartományom B3-tól B14-ig, tehát csak erre fog vonatkozni a formázás. Ez eddig szépen is működik és az esetek jelentős részében ennyi elég is nekünk - de mi van, ha esetleg ezt a feltételes formázást másolni szeretnénk? Rakjunk egy másik táblát a megformázott mellé:
Ez eddig szépen is működik és az esetek jelentős részében ennyi elég is nekünk - de mi van, ha esetleg ezt a feltételes formázást másolni szeretnénk? Rakjunk egy másik táblát a megformázott mellé: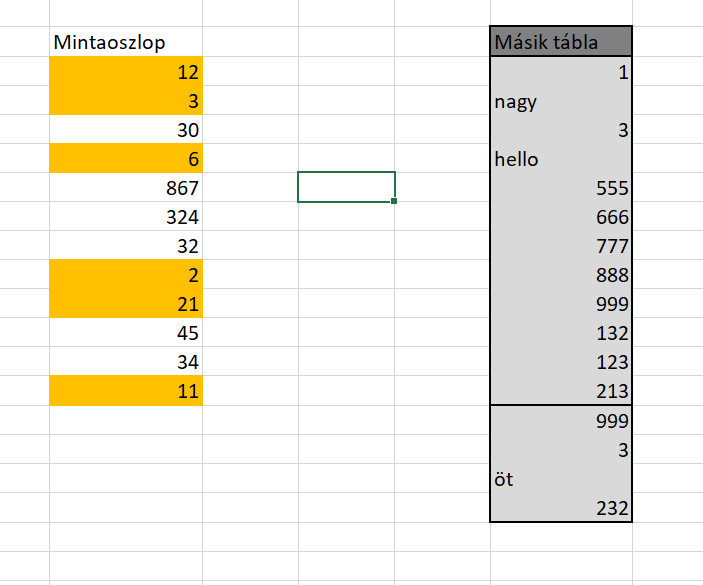 Jelöljük ki az eredeti táblát, majd nyomjunk egy CTRL+C-t és tegyük a vágólapra. Szimpla CTRL+V beillesztés helyett azonban nyomjunk jobb gombot az egerünkön, majd válasszuk a Paste Special menüt és utána még egyszer a Paste Special almenüt. Ezt fogjuk látni:
Jelöljük ki az eredeti táblát, majd nyomjunk egy CTRL+C-t és tegyük a vágólapra. Szimpla CTRL+V beillesztés helyett azonban nyomjunk jobb gombot az egerünkön, majd válasszuk a Paste Special menüt és utána még egyszer a Paste Special almenüt. Ezt fogjuk látni: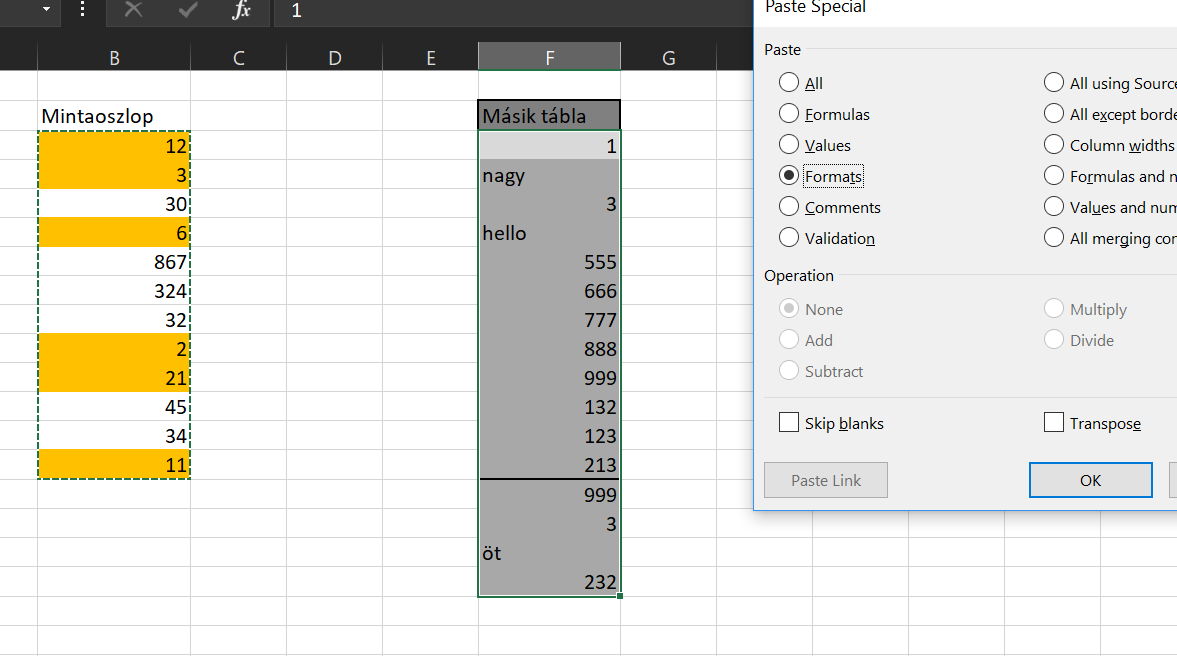 Válasszuk ki ezen a képernyőn a Paste Formats rádiógombot és nyomjunk okét:
Válasszuk ki ezen a képernyőn a Paste Formats rádiógombot és nyomjunk okét: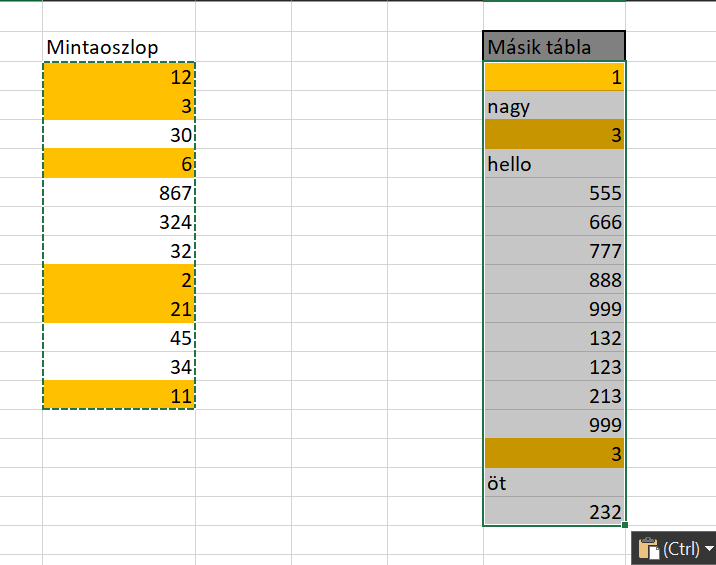 Ahogy látható, felülírtuk a második tábla formázását és átültettük az eredeti, első tábla formátumát - ezzel együtt pedig a Conditional Formattingot is. Viszont mi történik, ha a második tábla értékeit akarjuk beilleszteni az eredeti oszlopba, de úgy, hogy a Conditional Formatting ne vesszen el?
Ahogy látható, felülírtuk a második tábla formázását és átültettük az eredeti, első tábla formátumát - ezzel együtt pedig a Conditional Formattingot is. Viszont mi történik, ha a második tábla értékeit akarjuk beilleszteni az eredeti oszlopba, de úgy, hogy a Conditional Formatting ne vesszen el?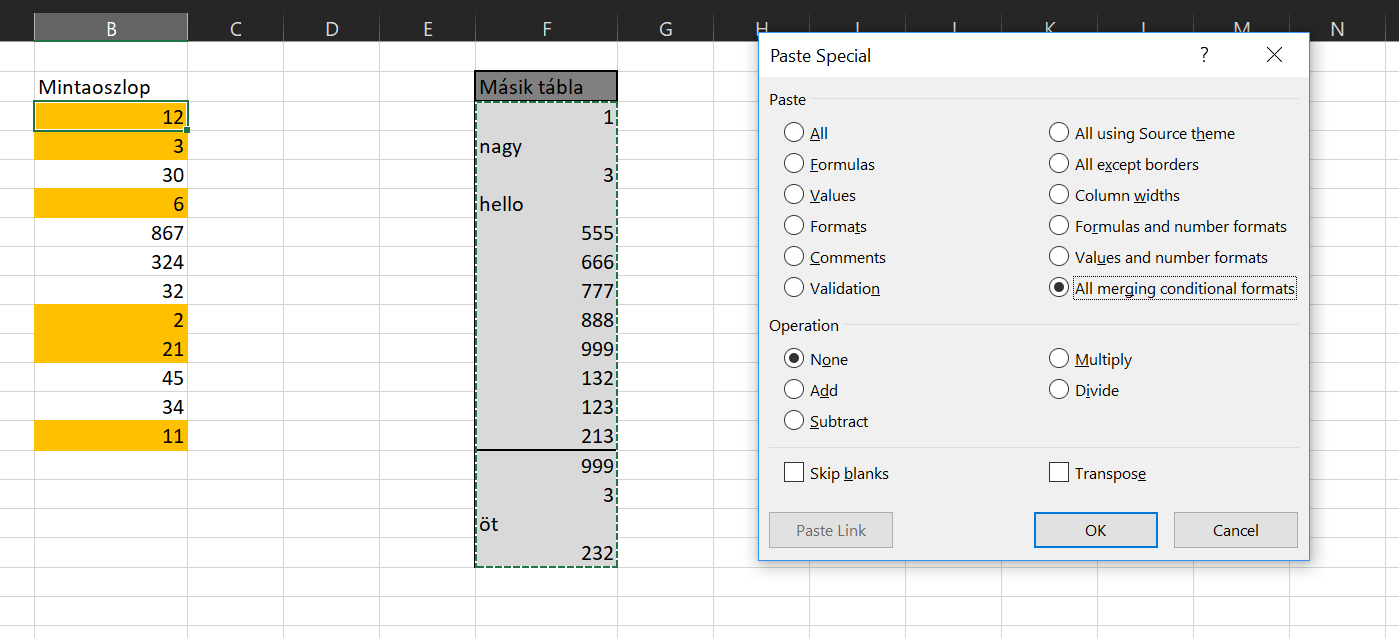 És itt válasszuk az
És itt válasszuk az 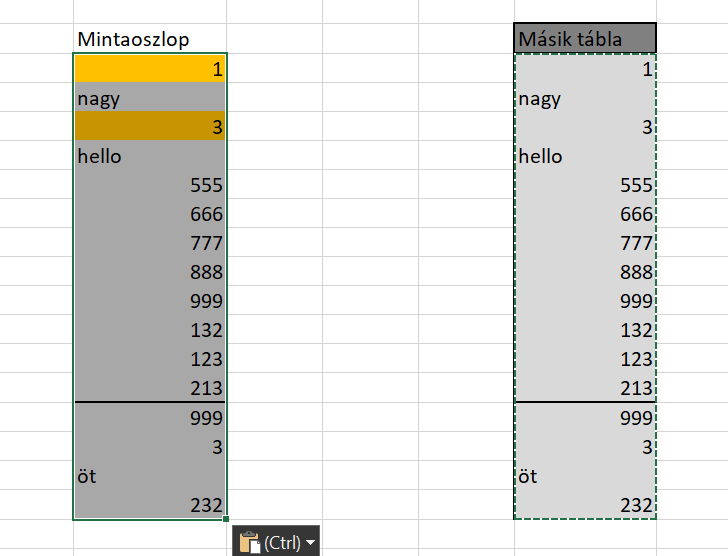 És itt látható is, hogy miért említettem még a poszt elején, hogy figyeljünk arra, a Conditional Formatting milyen tartományra kerül beállításra, ugyanis ahogy látható, az eredeti tartomány méretéig szépen működik a CF, de az utolsó hármas azért nem lett sárga hátterű, mert már kívül van az eredeti CF tartományán.
És itt látható is, hogy miért említettem még a poszt elején, hogy figyeljünk arra, a Conditional Formatting milyen tartományra kerül beállításra, ugyanis ahogy látható, az eredeti tartomány méretéig szépen működik a CF, de az utolsó hármas azért nem lett sárga hátterű, mert már kívül van az eredeti CF tartományán.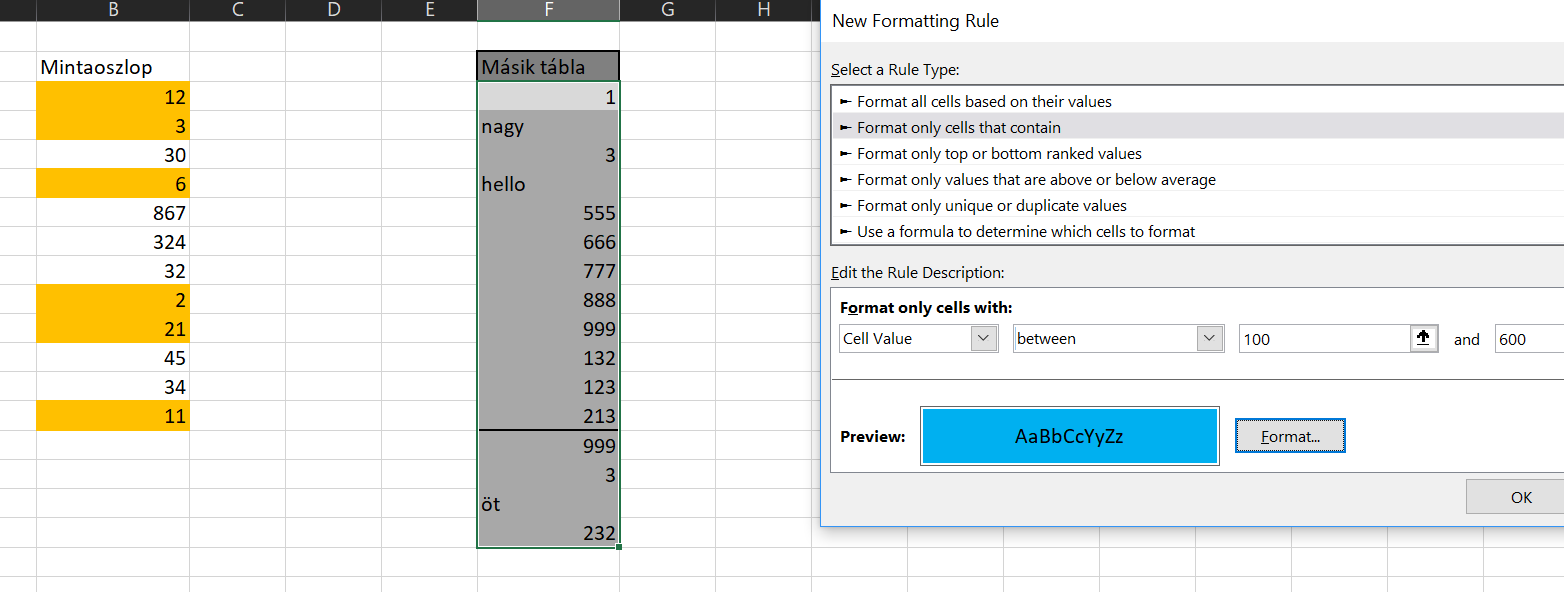 Ahogy látható, a 100 és 600 közötti számok hátterét szeretném kékre állítani:
Ahogy látható, a 100 és 600 közötti számok hátterét szeretném kékre állítani: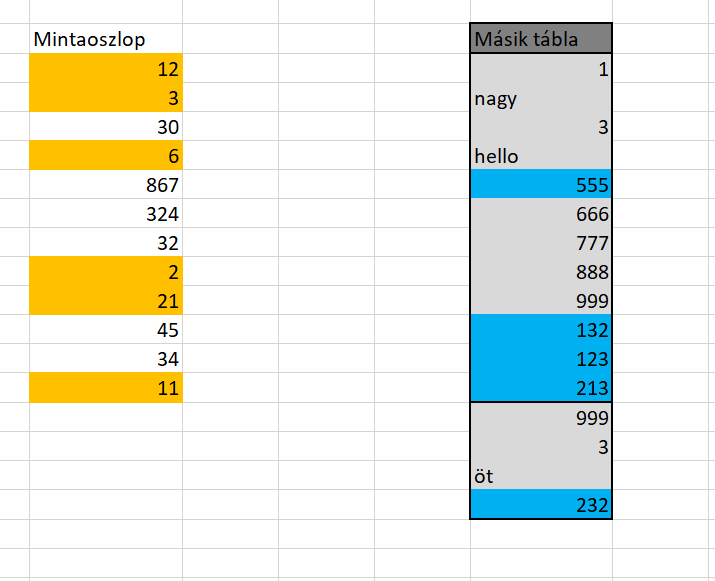 Ha ezután úgy szeretném a két tartományomat összemásolni, hogy mindkét CF megmaradjon, akkor szintén kijelölöm a másolandó tartományt, majd beillesztés előtt a Paste Special almenübe lépve ismét az
Ha ezután úgy szeretném a két tartományomat összemásolni, hogy mindkét CF megmaradjon, akkor szintén kijelölöm a másolandó tartományt, majd beillesztés előtt a Paste Special almenübe lépve ismét az 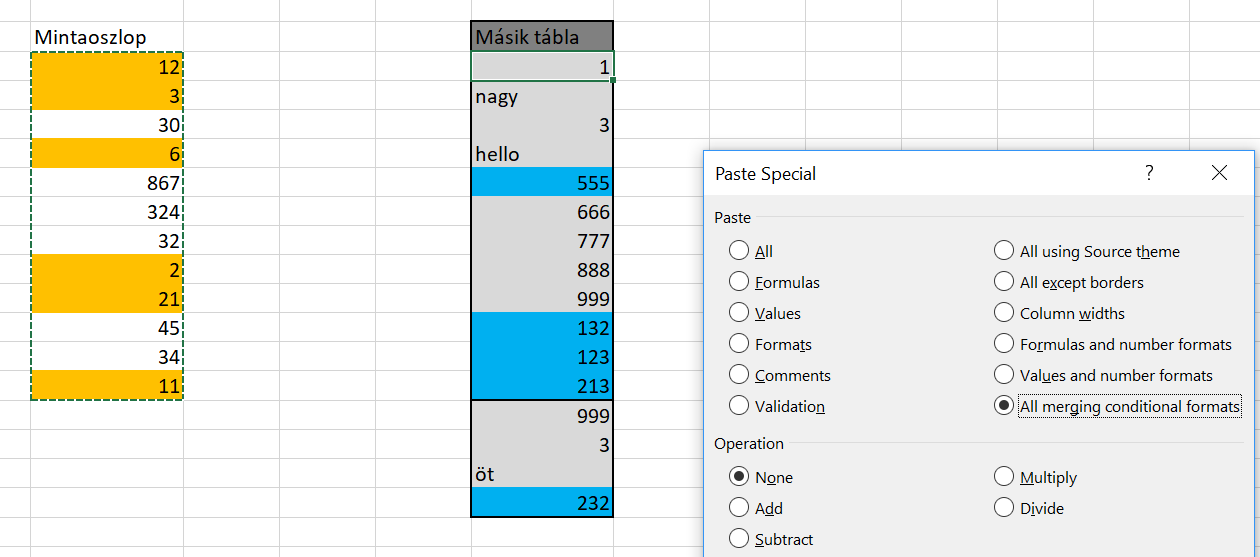 Ezzel pedig elértük, amit akartunk, de mivel az eredeti tartomány méretére volt a CF is méretezve, így a második táblában is csak ezen a tartományméreten lesz beállítva a két CF, méghozzá úgy, hogy a másolt tartomány feltétele lesz az elsőszámú feltétel:
Ezzel pedig elértük, amit akartunk, de mivel az eredeti tartomány méretére volt a CF is méretezve, így a második táblában is csak ezen a tartományméreten lesz beállítva a két CF, méghozzá úgy, hogy a másolt tartomány feltétele lesz az elsőszámú feltétel: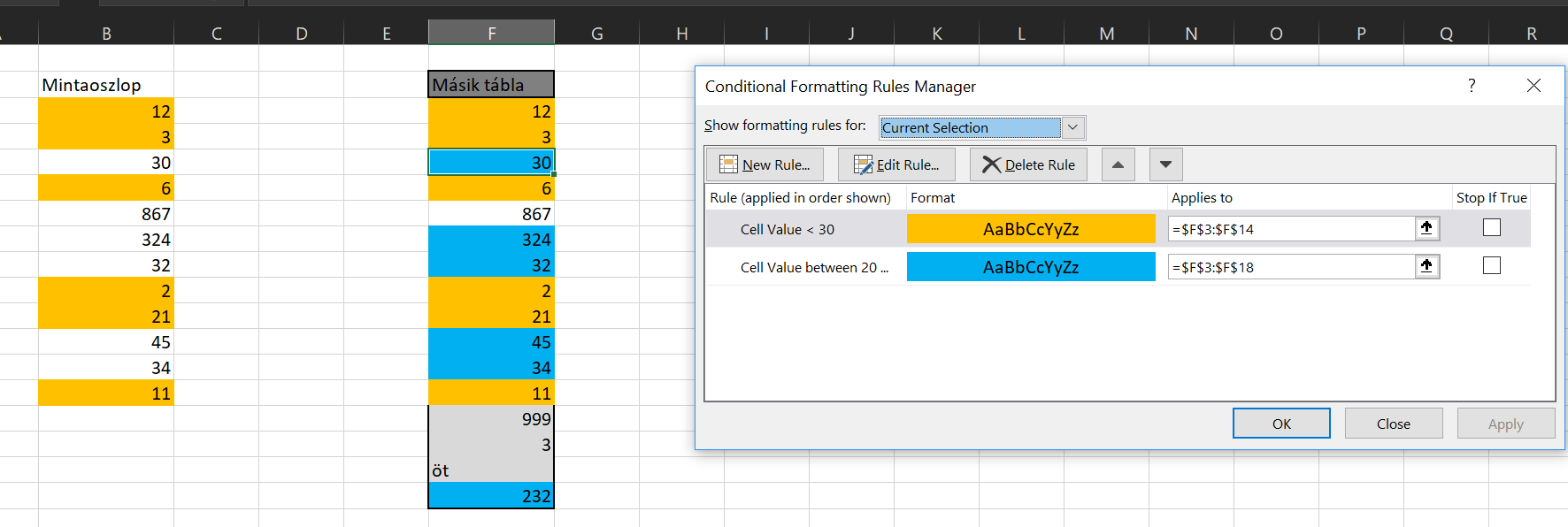 Az All merging conditional formats ismerete igencsak fontos ilyen jellegű másolásnál, ugyanis ha csak Insert Copied Cellst vagy sima Pastet használunk, akkor eléggé viccessé válhat a Conditional Formatting működése (egyes cellákon jól fog működni, másokon nem, új sorok beszúrása pedig szintén meg tudja dönteni a funkciót). Szóval jótanácsként tároljuk el elménkben ezt az opciót, minden Conditional Formatting másolásnál jusson eszünkbe!
Az All merging conditional formats ismerete igencsak fontos ilyen jellegű másolásnál, ugyanis ha csak Insert Copied Cellst vagy sima Pastet használunk, akkor eléggé viccessé válhat a Conditional Formatting működése (egyes cellákon jól fog működni, másokon nem, új sorok beszúrása pedig szintén meg tudja dönteni a funkciót). Szóval jótanácsként tároljuk el elménkben ezt az opciót, minden Conditional Formatting másolásnál jusson eszünkbe!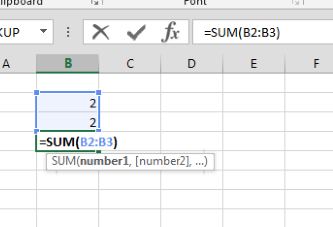 A feladat annyi lenne, hogy egy másik cellába olvastassuk ki ezt a függvényt, majd futtassuk is le, tehát egy másik cellába is kapjuk meg a szummánk eredményét. Az Excel ehhez már kínál nekünk beépített funkciót is, ez a FORMULATEXT nevű függvény, amely szépen vissza is adja szövegként a függvényünket:
A feladat annyi lenne, hogy egy másik cellába olvastassuk ki ezt a függvényt, majd futtassuk is le, tehát egy másik cellába is kapjuk meg a szummánk eredményét. Az Excel ehhez már kínál nekünk beépített funkciót is, ez a FORMULATEXT nevű függvény, amely szépen vissza is adja szövegként a függvényünket: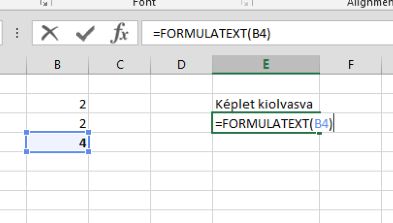
 Viszont a futtatáshoz szükségünk van egy aprócska kódra VBA-ban, úgyhogy gyorsan ugorjunk is be ALT+F11-gyel a VBA-editorba. A következő funkciót fogjuk definiálni egy modulban:
Viszont a futtatáshoz szükségünk van egy aprócska kódra VBA-ban, úgyhogy gyorsan ugorjunk is be ALT+F11-gyel a VBA-editorba. A következő funkciót fogjuk definiálni egy modulban: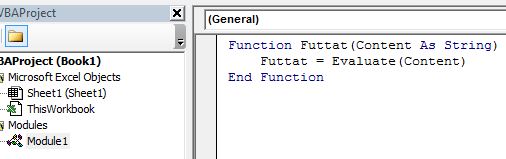 Innentől kezdve ezzel a custom funkcióval már végre tudjuk hajtani a FORMULATEXT segítségével kiszedett, szövegformátumú függvényt.
Innentől kezdve ezzel a custom funkcióval már végre tudjuk hajtani a FORMULATEXT segítségével kiszedett, szövegformátumú függvényt. 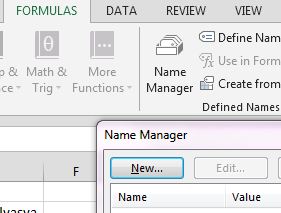
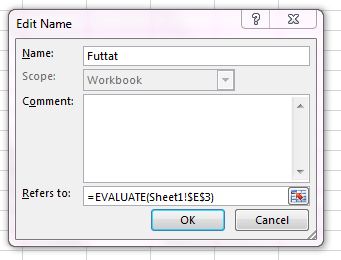 Fontos, hogy az EVALUATE kizárólag a Name managerben használható, ha nem hoztuk létre a custom funkciót, akkor nem tudjuk cellából közvetlenül meghívni. Szóval ha megvan a definált tartomány, akkor már csak beírjuk egy cellába és kész is vagyunk:
Fontos, hogy az EVALUATE kizárólag a Name managerben használható, ha nem hoztuk létre a custom funkciót, akkor nem tudjuk cellából közvetlenül meghívni. Szóval ha megvan a definált tartomány, akkor már csak beírjuk egy cellába és kész is vagyunk: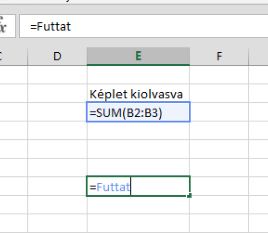
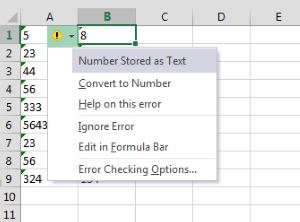 Le merném fogadni, hogy az Excellel dolgozók 99%-a rendszeresen találkozik azzal a hibával, amelyben Text formátumú cellákba kerülnek számok és emiatt például az erre a cellára hivatkozó képleteink nem igazán működnek megfelelően. Ha csak néhány esetről van szó, akkor simán átállítani a formátumot vagy a kis pöcök segítségével számmá konvertálni az értékeket megoldás lehet - viszont ez sok tízezer sornál hosszú-hosszú perceket jelent.
Le merném fogadni, hogy az Excellel dolgozók 99%-a rendszeresen találkozik azzal a hibával, amelyben Text formátumú cellákba kerülnek számok és emiatt például az erre a cellára hivatkozó képleteink nem igazán működnek megfelelően. Ha csak néhány esetről van szó, akkor simán átállítani a formátumot vagy a kis pöcök segítségével számmá konvertálni az értékeket megoldás lehet - viszont ez sok tízezer sornál hosszú-hosszú perceket jelent. Az első felugró ablakban Delimited opciót válasszuk, a másodikban a delimiterek elől vegyük ki a pipákat, tehát semmilyen elválasztót ne adjunk meg, a harmadik képernyőn pedig válasszunk General opciót az adatformátumra:
Az első felugró ablakban Delimited opciót válasszuk, a másodikban a delimiterek elől vegyük ki a pipákat, tehát semmilyen elválasztót ne adjunk meg, a harmadik képernyőn pedig válasszunk General opciót az adatformátumra: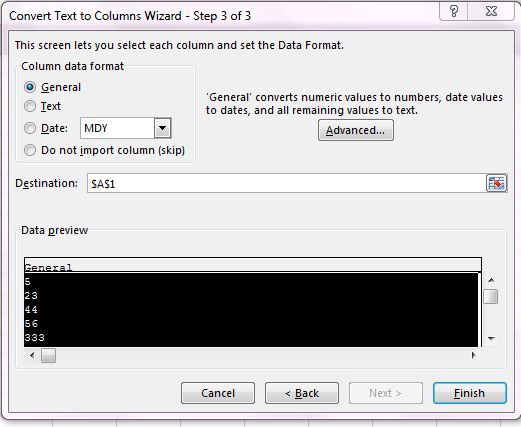 Ha a Finishre kattintunk, már látjuk is az eredményt:
Ha a Finishre kattintunk, már látjuk is az eredményt: A következő apró tanács a Pivot-táblákra vonatkozik (amelyek egyébként képesek néha az őrületbe kergetni a felhasználót, annyi korlátozás van bennük), ugyanis könnyen bele lehet futni abba a problémába, hogy egyszerűen nem lehet szűrőt bekapcsolni a táblára (vagy akár sortolni sem lehet), ahogy ez a következő képen látható is:
A következő apró tanács a Pivot-táblákra vonatkozik (amelyek egyébként képesek néha az őrületbe kergetni a felhasználót, annyi korlátozás van bennük), ugyanis könnyen bele lehet futni abba a problémába, hogy egyszerűen nem lehet szűrőt bekapcsolni a táblára (vagy akár sortolni sem lehet), ahogy ez a következő képen látható is: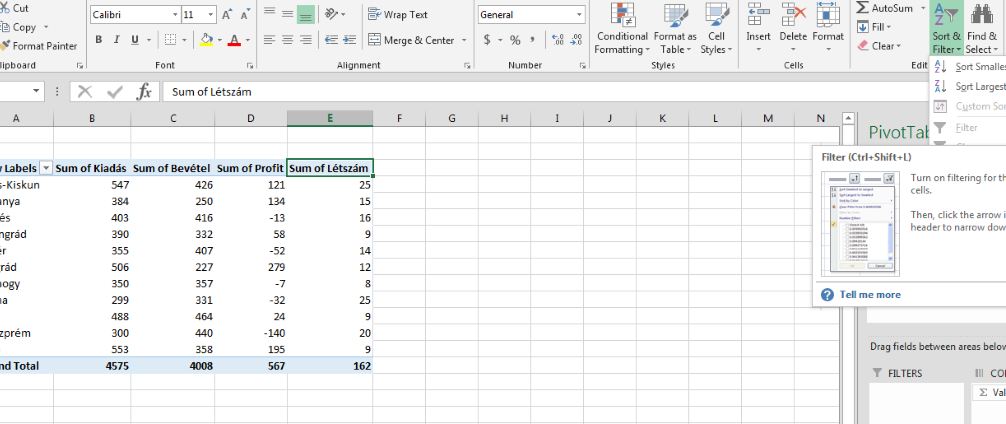 Kicsit elrejtve, de azért jól látható, hogy a Filter funkció szürke, tehát nem használható, hiába akarnánk bekapcsolni a Pivot-táblán állva. A megoldás a billentyűkombináció használata, azaz ALT+A+T lenyomása után már el is érjük a kívánt hatást:
Kicsit elrejtve, de azért jól látható, hogy a Filter funkció szürke, tehát nem használható, hiába akarnánk bekapcsolni a Pivot-táblán állva. A megoldás a billentyűkombináció használata, azaz ALT+A+T lenyomása után már el is érjük a kívánt hatást: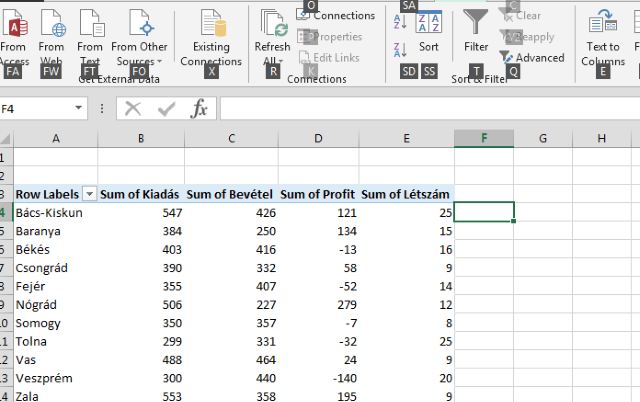
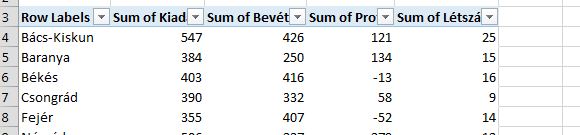 A poszt végére pedig (afféle harmadik tanácsként) jöjjön egy fontos emlékeztető a Conditional Formattingról, méghozzá feltételes formázásunk kiterjesztésére vonatkozóan. Adott a következő kis tábla:
A poszt végére pedig (afféle harmadik tanácsként) jöjjön egy fontos emlékeztető a Conditional Formattingról, méghozzá feltételes formázásunk kiterjesztésére vonatkozóan. Adott a következő kis tábla: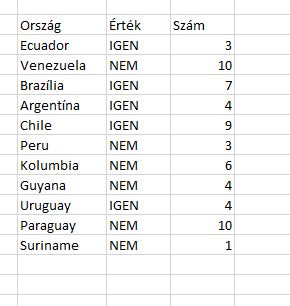 Három különböző variációban kellene színeznünk a táblában, elsőként azokat a sorokat kellene sárgára színeznünk, amelyekben a C oszlopban szereplő érték IGEN, másodikként a B oszlop értékeit kell a C oszlop IGEN-jei esetén sárgára színezni, végül pedig a teljes sort ki kell színeznünk, ahol a C oszlop IGEN-t tartalmaz.
Három különböző variációban kellene színeznünk a táblában, elsőként azokat a sorokat kellene sárgára színeznünk, amelyekben a C oszlopban szereplő érték IGEN, másodikként a B oszlop értékeit kell a C oszlop IGEN-jei esetén sárgára színezni, végül pedig a teljes sort ki kell színeznünk, ahol a C oszlop IGEN-t tartalmaz.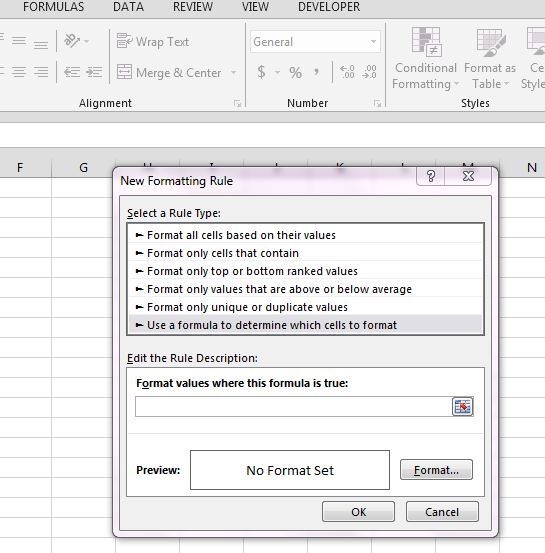 Ha csak a C oszlop IGEN értékeit akarjuk színezni:
Ha csak a C oszlop IGEN értékeit akarjuk színezni: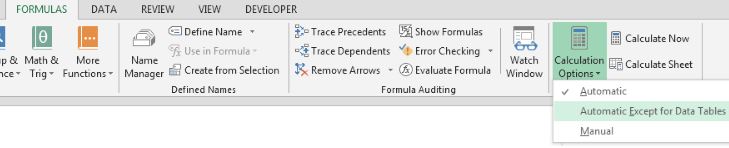 Másrészt a File menüben megnyitható Excel Options Formulas almenüjében:
Másrészt a File menüben megnyitható Excel Options Formulas almenüjében: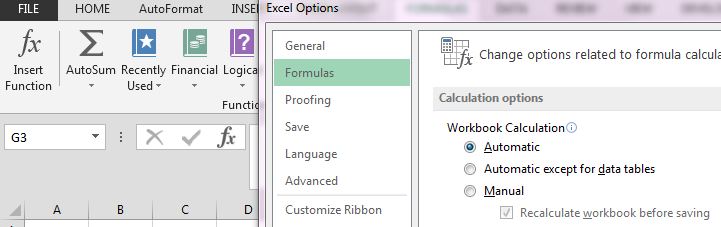 Azt valószínűleg a felhasználók 90%-a pontosan tudja is, hogy ez mire való, azaz ha Automatic calculationt állítunk be, akkor értelemszerűen az Excel újrakalkulál mindent az adott munkafüzetben, amikor egy érték változik vagy valamilyen meghatározott esemény történik (sorok beszúrása például), míg a Manual calculation csak akkor számít újra mindent, ha erre a felhasználó utasítást ad (mondjuk a Calculate sheet funkcióval).
Azt valószínűleg a felhasználók 90%-a pontosan tudja is, hogy ez mire való, azaz ha Automatic calculationt állítunk be, akkor értelemszerűen az Excel újrakalkulál mindent az adott munkafüzetben, amikor egy érték változik vagy valamilyen meghatározott esemény történik (sorok beszúrása például), míg a Manual calculation csak akkor számít újra mindent, ha erre a felhasználó utasítást ad (mondjuk a Calculate sheet funkcióval).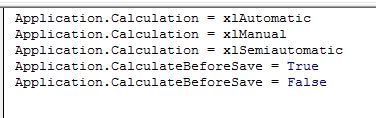 Elég gyakran előfordul kódolás közben, hogy a sebesség érdekében a szubrutin kezdetén kikapcsolásra kerül az automatikus kalkuláció és csak a végén kerül ismét bekapcsolásra - ez pedig azzal a kockázattal jár, hogy ha mondjuk leállítjuk valahol a kódunkat, akkor a beállítás úgy marad, ahogy éppen a kód szerint be volt állítva.
Elég gyakran előfordul kódolás közben, hogy a sebesség érdekében a szubrutin kezdetén kikapcsolásra kerül az automatikus kalkuláció és csak a végén kerül ismét bekapcsolásra - ez pedig azzal a kockázattal jár, hogy ha mondjuk leállítjuk valahol a kódunkat, akkor a beállítás úgy marad, ahogy éppen a kód szerint be volt állítva. Ezután ha megnézzük a Formulas ribbonfül alatt, akkor a kalkulációs mód még mindig Automatic:
Ezután ha megnézzük a Formulas ribbonfül alatt, akkor a kalkulációs mód még mindig Automatic: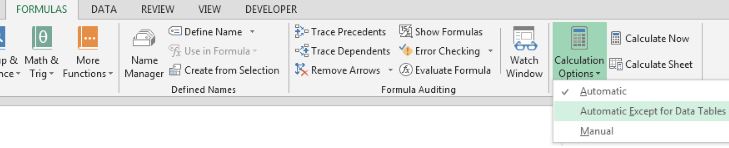 De ha a File - Excel Options alatt megnézzük, akkor már Manualon áll a rádiógomb. Persze megnyugodhatunk, alapvetően ekkor is Automatic calculation beállításon vagyunk, de eléggé megtévesztő, hogy a File Options alatt mást mutat, mint a Formulasnál.
De ha a File - Excel Options alatt megnézzük, akkor már Manualon áll a rádiógomb. Persze megnyugodhatunk, alapvetően ekkor is Automatic calculation beállításon vagyunk, de eléggé megtévesztő, hogy a File Options alatt mást mutat, mint a Formulasnál.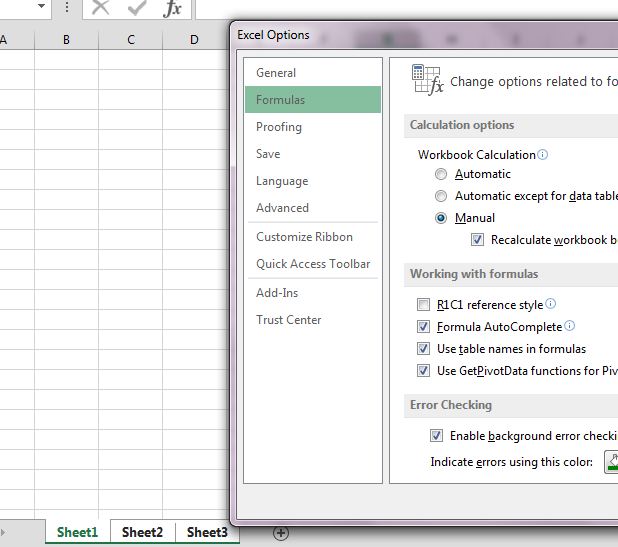
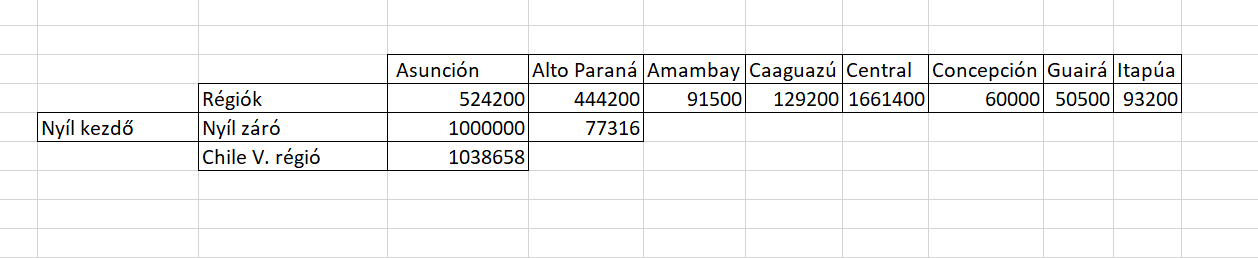 Az egyik sorban több paraguayi régiót láthatunk felsorolva az adott régió lakosságszámával egyetemben, legalul pedig a chilei V. régió lélekszámát láthatjuk - a célunk pedig az lesz, hogy akár egy bar charton, akár egy column diagramon egy nyíllal mutassuk meg, hogy az összes paraguayi régiót figyelembevéve hol helyezkedik el a chilei V. régió, már ami a lakosok számát illeti.
Az egyik sorban több paraguayi régiót láthatunk felsorolva az adott régió lakosságszámával egyetemben, legalul pedig a chilei V. régió lélekszámát láthatjuk - a célunk pedig az lesz, hogy akár egy bar charton, akár egy column diagramon egy nyíllal mutassuk meg, hogy az összes paraguayi régiót figyelembevéve hol helyezkedik el a chilei V. régió, már ami a lakosok számát illeti.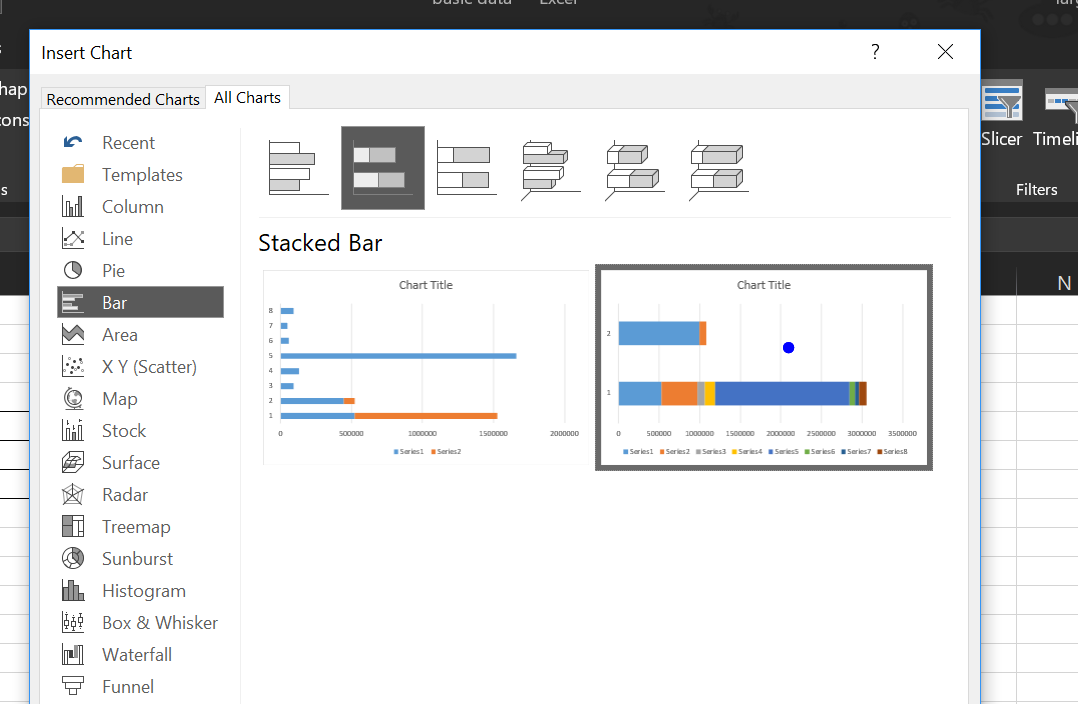 Ahogy látható, az első sorban különféle színekkel ábrázolva ott vannak a paraguayi régiók, a második sor pedig a nyílunk kezdő értékét és záró értékét mutatja:
Ahogy látható, az első sorban különféle színekkel ábrázolva ott vannak a paraguayi régiók, a második sor pedig a nyílunk kezdő értékét és záró értékét mutatja: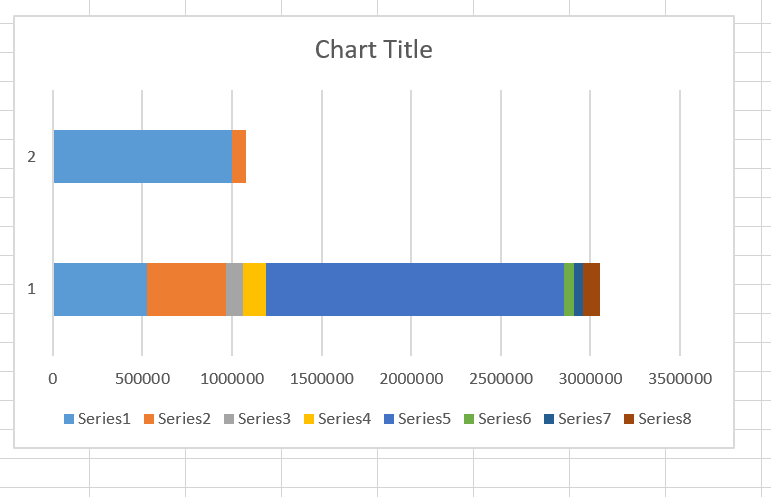 Tehát ha beszúrtuk, a fenti kép szerinti eredménnyel, akkor még mindig az Insert ribbonfül alatt maradva, az Illustrations szekció Shapes menüjéből válasszunk egy nekünk szükséges ikont (én nyilat választok), majd szúrjuk be:
Tehát ha beszúrtuk, a fenti kép szerinti eredménnyel, akkor még mindig az Insert ribbonfül alatt maradva, az Illustrations szekció Shapes menüjéből válasszunk egy nekünk szükséges ikont (én nyilat választok), majd szúrjuk be: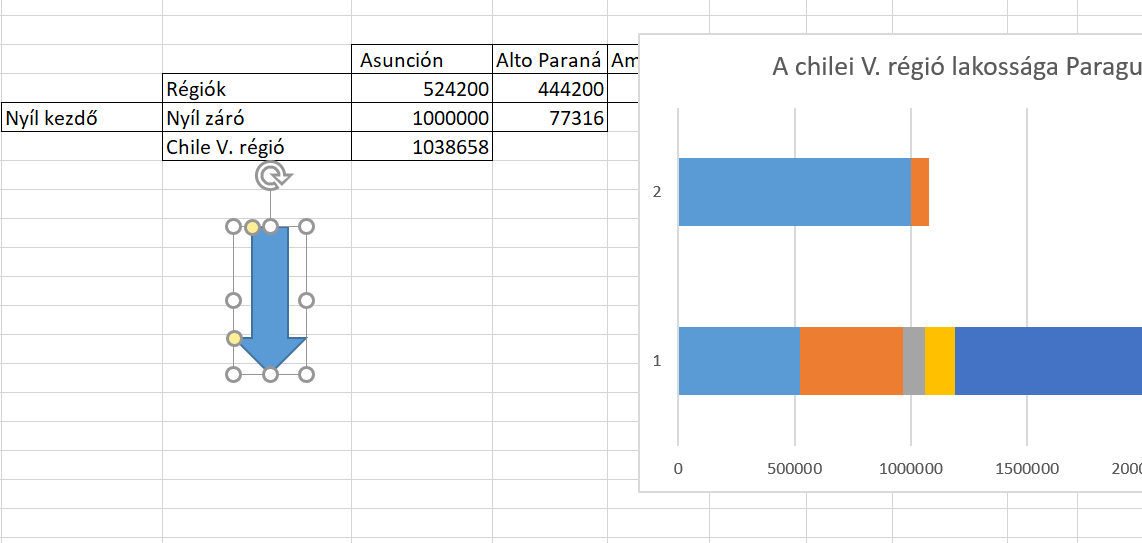 Ezután a nyílon állva formázzuk meg, ahogy szeretnénk, majd nyomjunk egy CTRL+C-t - ezután pedig jelöljük ki a chartunk első sorában a kisebbik részt (tehát a nyíl kezdő és záró értéke közötti kis kockát és nyomjunk egy CTRL+V-t. Ezt fogjuk kapni:
Ezután a nyílon állva formázzuk meg, ahogy szeretnénk, majd nyomjunk egy CTRL+C-t - ezután pedig jelöljük ki a chartunk első sorában a kisebbik részt (tehát a nyíl kezdő és záró értéke közötti kis kockát és nyomjunk egy CTRL+V-t. Ezt fogjuk kapni: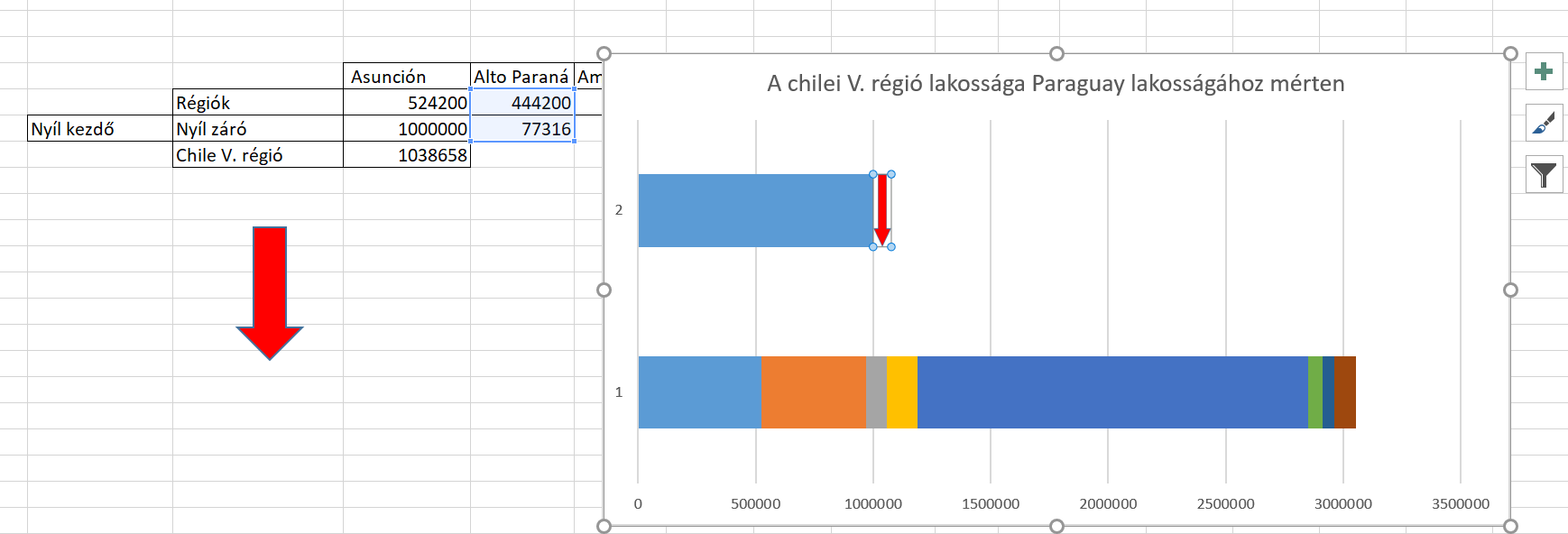 És ezzel valószínűleg már mindenki látja, merre tartunk a történetben, hiszen a következő lépésként a második sorunk első szekcióját fogjuk megformázni (ez a nyíl előtti rész). Jelöljük ki, majd a Format ribbonfül Shape Styles szekciójából a Fill és Outline funkciók segítségével tüntessük el a kitöltést és a határokat is:
És ezzel valószínűleg már mindenki látja, merre tartunk a történetben, hiszen a következő lépésként a második sorunk első szekcióját fogjuk megformázni (ez a nyíl előtti rész). Jelöljük ki, majd a Format ribbonfül Shape Styles szekciójából a Fill és Outline funkciók segítségével tüntessük el a kitöltést és a határokat is: Még egy lépésünk van hátra, kattintsunk valamelyik Series értékre (ezek a színes kis kockáink) jobb egérgombbal, majd a jobboldalt megjelenő Format Data Series menüben a Series Overlap értéket állítsuk 100%-ra, a Gap Width értéket pedig 0%-ra (tehát ne legyen a két barunk között semmiféle távolság):
Még egy lépésünk van hátra, kattintsunk valamelyik Series értékre (ezek a színes kis kockáink) jobb egérgombbal, majd a jobboldalt megjelenő Format Data Series menüben a Series Overlap értéket állítsuk 100%-ra, a Gap Width értéket pedig 0%-ra (tehát ne legyen a két barunk között semmiféle távolság):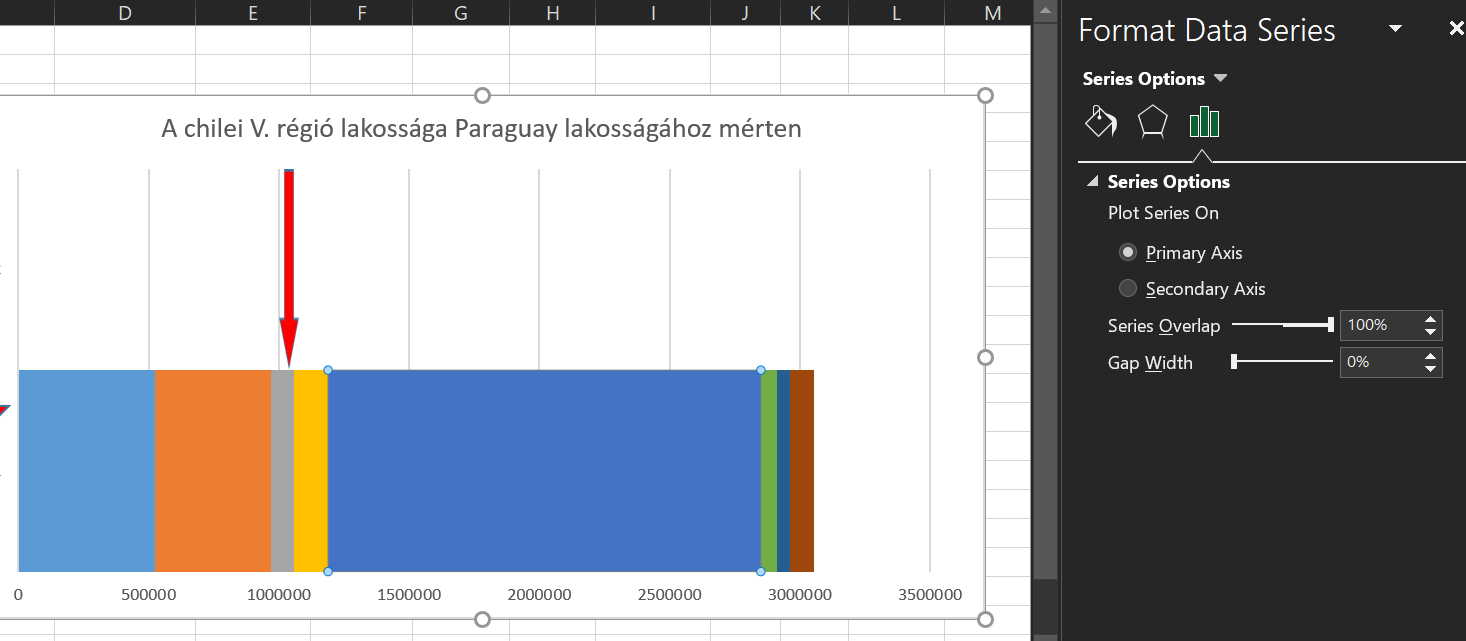 Ezzel pedig ezt kaptuk:
Ezzel pedig ezt kaptuk: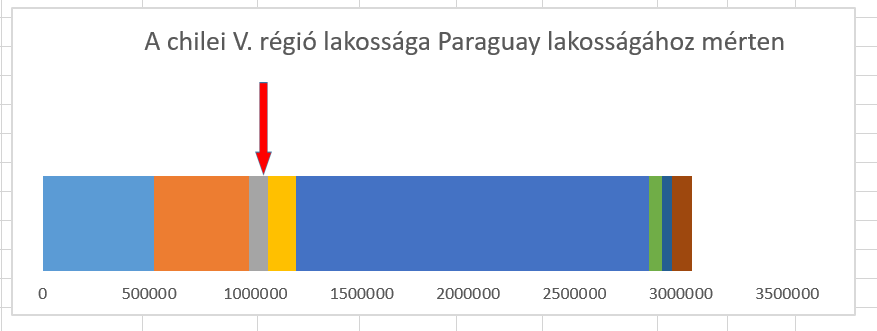 Innentől kezdve pedig már nincs túl sok feladatunk, szimplán úgy dolgozzuk ki a kalkulációkat a nyíl kezdő és záró értékére, hogy azok folyamatosan frissüljenek az adatainkból és így a nyíl is úgy fog mozogni, ahogy szeretnénk és ahogy szükséges.
Innentől kezdve pedig már nincs túl sok feladatunk, szimplán úgy dolgozzuk ki a kalkulációkat a nyíl kezdő és záró értékére, hogy azok folyamatosan frissüljenek az adatainkból és így a nyíl is úgy fog mozogni, ahogy szeretnénk és ahogy szükséges.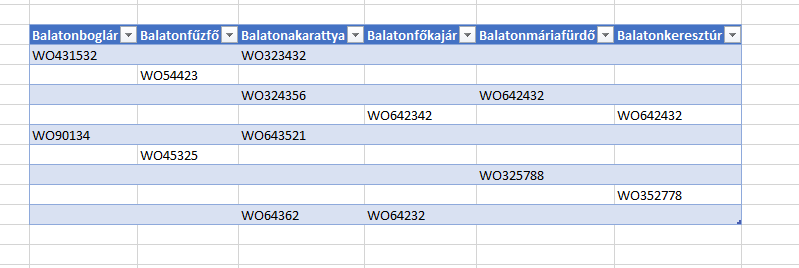 Ahogy látható, üres sorok és értékek összevisszaságából áll, a célunk pedig az értékek kinyerése lenne egyetlen oszlopba, figyelembe véve azt is, hogy egy sorban esetleg több érték is szerepelhet. Első lépésként a táblán állva lépjünk a Data ribbonfülre, majd a Get & Transform Data szekcióból válasszuk a From Table/Range opciót:
Ahogy látható, üres sorok és értékek összevisszaságából áll, a célunk pedig az értékek kinyerése lenne egyetlen oszlopba, figyelembe véve azt is, hogy egy sorban esetleg több érték is szerepelhet. Első lépésként a táblán állva lépjünk a Data ribbonfülre, majd a Get & Transform Data szekcióból válasszuk a From Table/Range opciót:
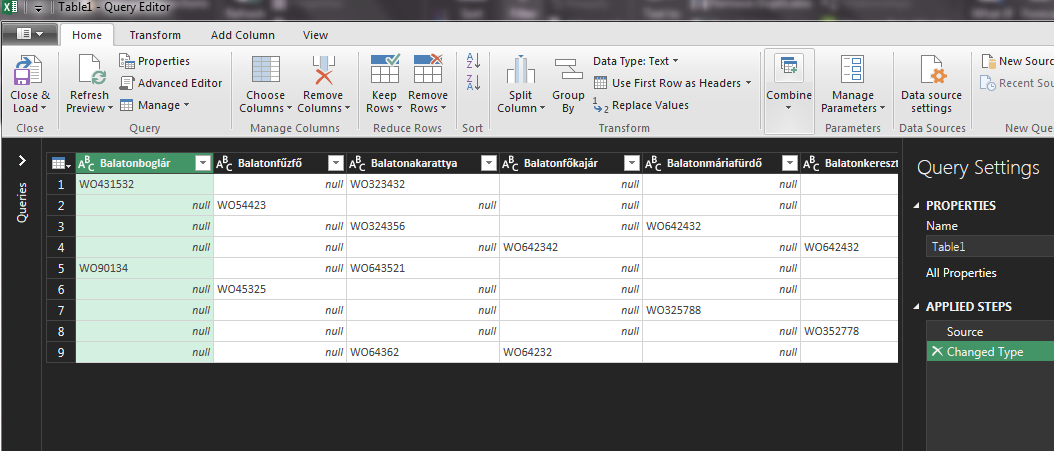 Fogjuk és jelöljük ki az összes oszlopot, de legalábbis azokat mindenképpen, amelyeket az egyesítésben szeretnénk figyelembevenni (itt is simán működik a Shift vagy Ctrl segítségével történő kijelölés), majd a Transform ribbonfül alatt keressük meg a Text Column szekciót, azon belül is a Merge Columns funkciót:
Fogjuk és jelöljük ki az összes oszlopot, de legalábbis azokat mindenképpen, amelyeket az egyesítésben szeretnénk figyelembevenni (itt is simán működik a Shift vagy Ctrl segítségével történő kijelölés), majd a Transform ribbonfül alatt keressük meg a Text Column szekciót, azon belül is a Merge Columns funkciót: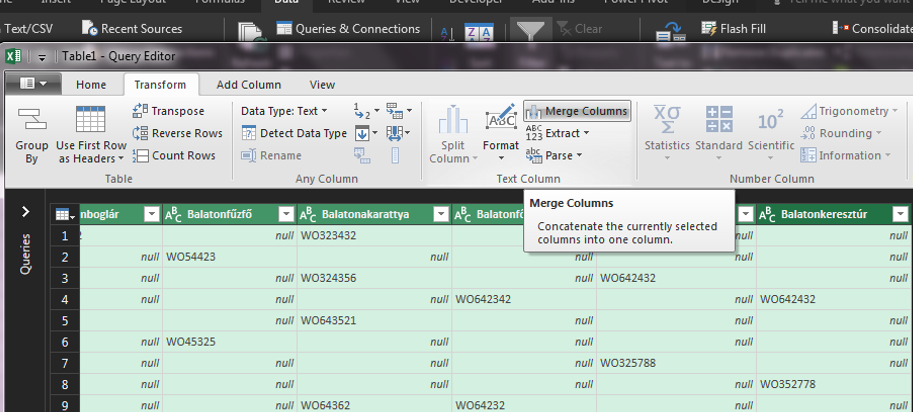 A felugró ablakban kiválaszthatjuk az új oszlop nevét, majd azt is, hogy az egy sorban szereplő több érték esetén milyen elválasztót szeretnénk használni:
A felugró ablakban kiválaszthatjuk az új oszlop nevét, majd azt is, hogy az egy sorban szereplő több érték esetén milyen elválasztót szeretnénk használni: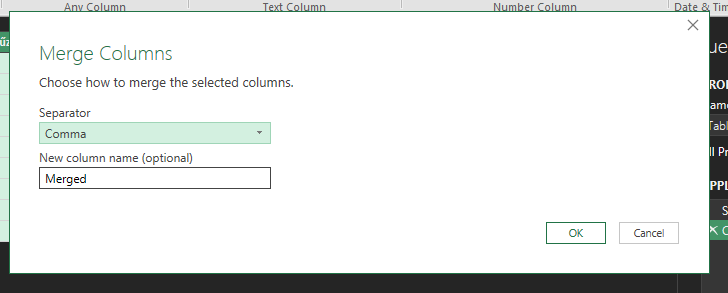 Én most vesszővel fogom elválasztani az értékeket és az oszlop neve maradt a defaultként felkínált Merged. Ahogy látható, az OK gomb lenyomása után el is készült az új oszlopunk, ami vesszővel elválasztva tartalmazza a többi oszlop értékét. Kattintsunk erre az oszlopra jobb egérgombbal, majd a felugró menüből válasszuk a Split Column lehetőséget, azon belül pedig a By Delimitert:
Én most vesszővel fogom elválasztani az értékeket és az oszlop neve maradt a defaultként felkínált Merged. Ahogy látható, az OK gomb lenyomása után el is készült az új oszlopunk, ami vesszővel elválasztva tartalmazza a többi oszlop értékét. Kattintsunk erre az oszlopra jobb egérgombbal, majd a felugró menüből válasszuk a Split Column lehetőséget, azon belül pedig a By Delimitert: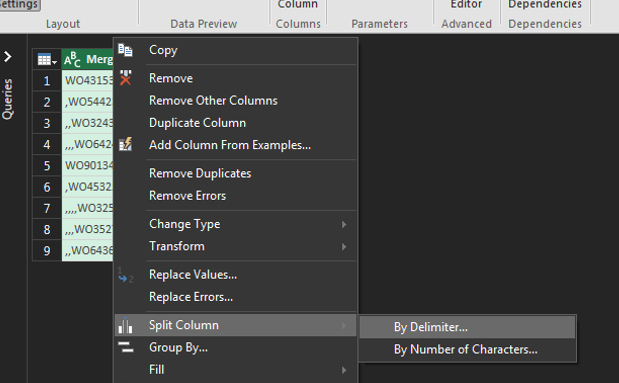 Ugyebár most azt akarjuk elérni, hogy az oszlopunkban lévő értékeket vesszők nélkül, külön-külön sorokban jelenítsük meg, így a felugró ablakban egyrészt adjuk meg fentebb a vessző delimiter-típust, lentebb pedig azt, hogy sorokba akarjuk rendezni a szétválasztás után az értékeket:
Ugyebár most azt akarjuk elérni, hogy az oszlopunkban lévő értékeket vesszők nélkül, külön-külön sorokban jelenítsük meg, így a felugró ablakban egyrészt adjuk meg fentebb a vessző delimiter-típust, lentebb pedig azt, hogy sorokba akarjuk rendezni a szétválasztás után az értékeket: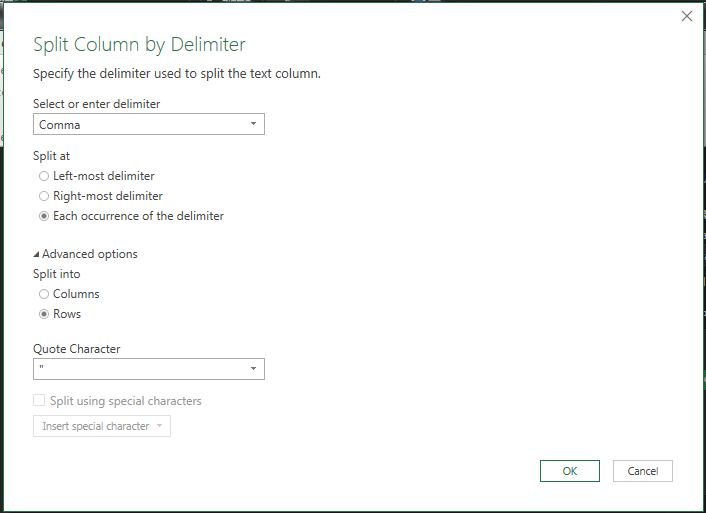 Ezzel már majdnem kész is vagyunk, a query editor ugyanis létrehozta az új oszlopot, annyi problémával, hogy vannak még üres soraink is - ezeket egyszerűen szűrjük ki:
Ezzel már majdnem kész is vagyunk, a query editor ugyanis létrehozta az új oszlopot, annyi problémával, hogy vannak még üres soraink is - ezeket egyszerűen szűrjük ki: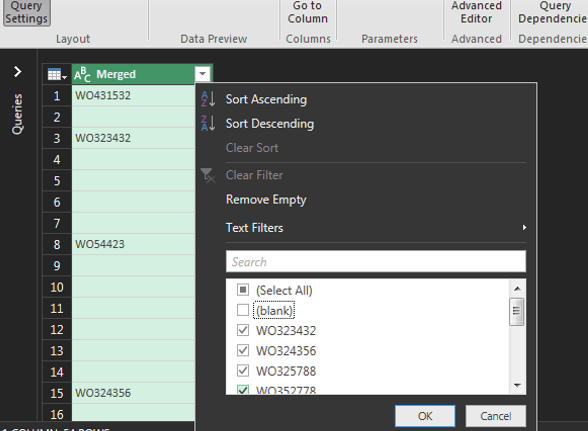 Az így kapott eredményt aztán a Home ribbonfül Close & Load funkciójával töltsük vissza Excelbe:
Az így kapott eredményt aztán a Home ribbonfül Close & Load funkciójával töltsük vissza Excelbe: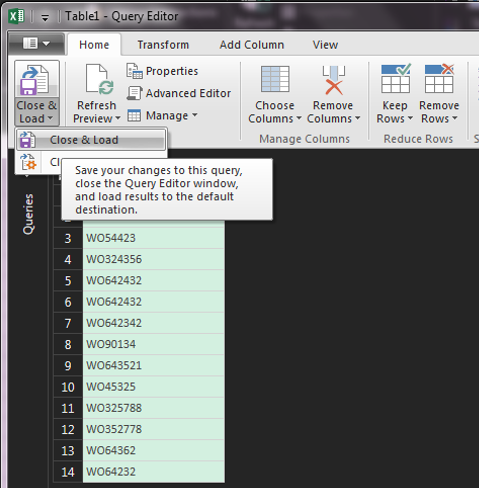 És meg is van, amit szerettünk volna:
És meg is van, amit szerettünk volna: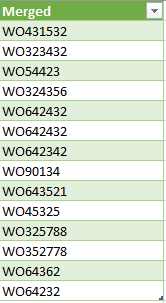
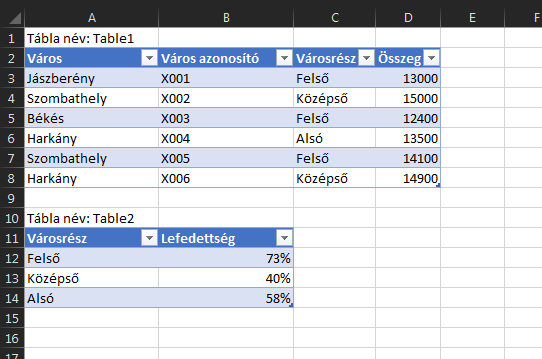 Hangsúlyozom, roppant leegyszerűsített példát használunk, a célunk szimplán egy VLOOKUP végrehajtása lesz, de PowerQuery segítségével, amelyen keresztül látni fogjuk, hogy ha a PQ-t használjuk, akkor nem igazán számít, hogy balra vannak az eredményértékek a keresett értékünktől, nem számít az sem, hogy több oszlopból kell kulcsot képeznünk és az sem fog már minket zavarni, ha egy kulcshoz több találatunk lehet - a PowerQuery mindent megold. Szóval a mai példában az a célunk, hogy a második számú tábla értékeihez a Városrész kulcs alapján keressük be az első táblánk megfelelő sorait.
Hangsúlyozom, roppant leegyszerűsített példát használunk, a célunk szimplán egy VLOOKUP végrehajtása lesz, de PowerQuery segítségével, amelyen keresztül látni fogjuk, hogy ha a PQ-t használjuk, akkor nem igazán számít, hogy balra vannak az eredményértékek a keresett értékünktől, nem számít az sem, hogy több oszlopból kell kulcsot képeznünk és az sem fog már minket zavarni, ha egy kulcshoz több találatunk lehet - a PowerQuery mindent megold. Szóval a mai példában az a célunk, hogy a második számú tábla értékeihez a Városrész kulcs alapján keressük be az első táblánk megfelelő sorait.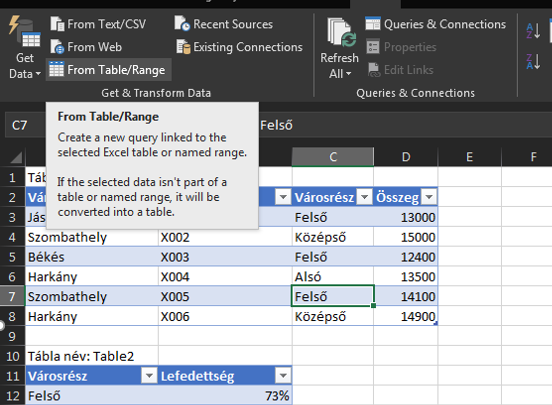 Ezzel be is töltöttük az adott táblát a Query editorba. Viszont mivel több táblánk van, a Query Editorban a Home ribbonfül alatt a Close & Load funkciócsoportból válasszuk ki a Close & Load To... opciót:
Ezzel be is töltöttük az adott táblát a Query editorba. Viszont mivel több táblánk van, a Query Editorban a Home ribbonfül alatt a Close & Load funkciócsoportból válasszuk ki a Close & Load To... opciót: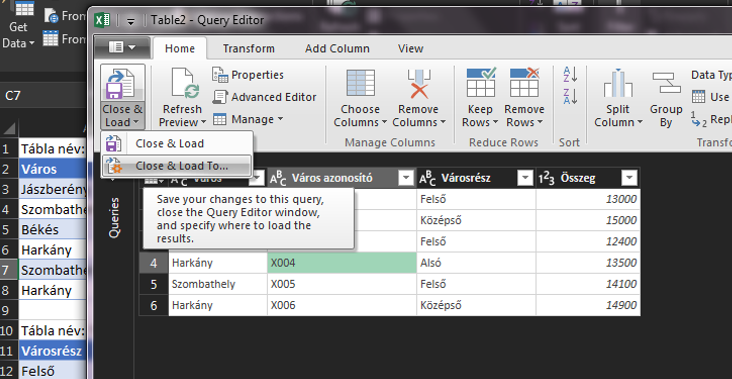 Majd válasszuk ki a következő táblánkat Only Create Connection és "Add this data to the Data Model" opciók kiválasztásával és kattintsunk az OK gombra:
Majd válasszuk ki a következő táblánkat Only Create Connection és "Add this data to the Data Model" opciók kiválasztásával és kattintsunk az OK gombra: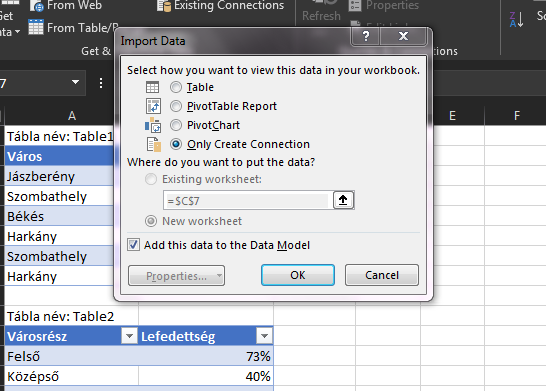 Látható is, hogy jobb oldalt megjelent a Queries & Connections menü, benne a két táblánkkal és soraikkal:
Látható is, hogy jobb oldalt megjelent a Queries & Connections menü, benne a két táblánkkal és soraikkal: Ha valamelyikre duplán kattintunk, visszajutunk a Query Editorba. Itt álljunk rá arra a táblára, amihez akarunk értékeket bekeresni, majd a Home ribbonfül Combine szekciójából válasszuk ki a Merge Queries funkciót:
Ha valamelyikre duplán kattintunk, visszajutunk a Query Editorba. Itt álljunk rá arra a táblára, amihez akarunk értékeket bekeresni, majd a Home ribbonfül Combine szekciójából válasszuk ki a Merge Queries funkciót: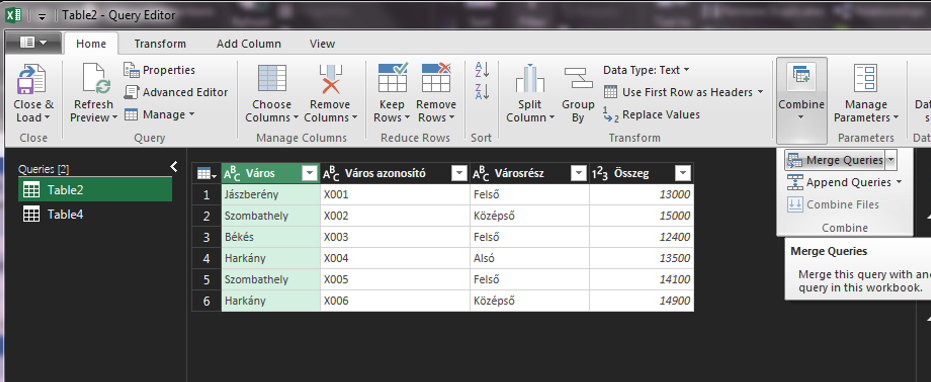 És most jön egy fontos lépés, a felugró Merge ablakban, az első részben ugyebár ott lesz az a táblánk, amihez értékeket akarunk keresni, a második részhez pedig válasszuk ki azt a a táblát, amelyik tartalmazza a bekeresendő értékeket - Join típusként (Join Kind) pedig válasszuk ki a Left Outer típust:
És most jön egy fontos lépés, a felugró Merge ablakban, az első részben ugyebár ott lesz az a táblánk, amihez értékeket akarunk keresni, a második részhez pedig válasszuk ki azt a a táblát, amelyik tartalmazza a bekeresendő értékeket - Join típusként (Join Kind) pedig válasszuk ki a Left Outer típust: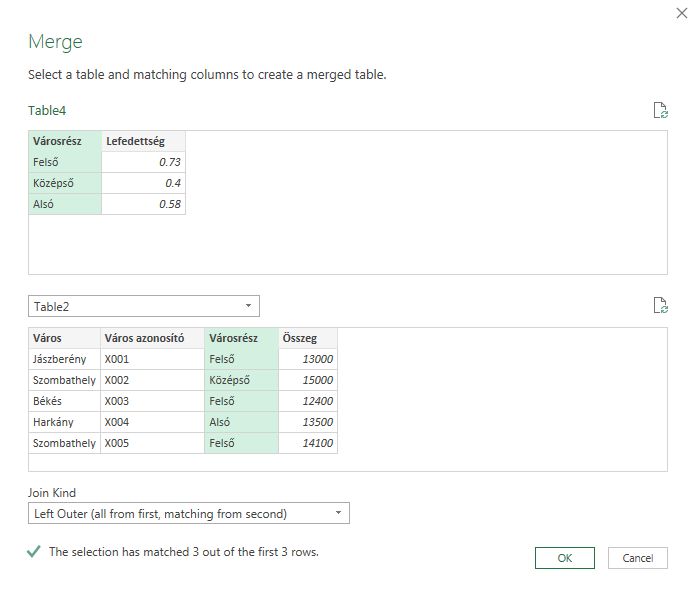 Ezt fogjuk látni a Query Editorban - megjelent a két oszlopunk mellett egy harmadik, Table tartalommal:
Ezt fogjuk látni a Query Editorban - megjelent a két oszlopunk mellett egy harmadik, Table tartalommal: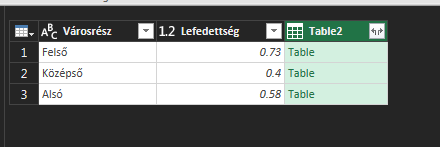 És ha a Table oszlopnév melletti két kis nyílra kattintunk, azonnal kibővül a táblánk és látni fogjuk, hogy sikerrel behoztuk a két baloldali oszlopunkat (erre szolgált a Left Outer Join típus):
És ha a Table oszlopnév melletti két kis nyílra kattintunk, azonnal kibővül a táblánk és látni fogjuk, hogy sikerrel behoztuk a két baloldali oszlopunkat (erre szolgált a Left Outer Join típus):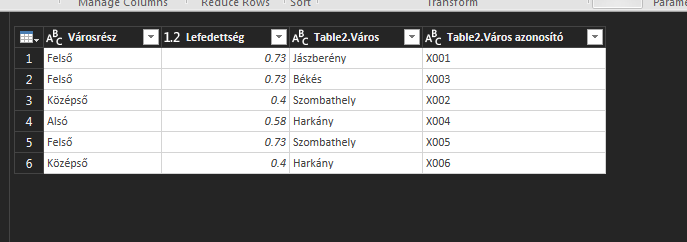 Ezután ha bezártuk a Query Editort, azt láthatjuk, hogy a jobboldali Queries & Connections menüben a második táblánk sorainak száma megnövekedett - hiszen behoztuk hozzá az összes egyedi értéket. Kattintsunk rá jobb gombbal, majd a Context menüből válasszuk ki a Load To menüt:
Ezután ha bezártuk a Query Editort, azt láthatjuk, hogy a jobboldali Queries & Connections menüben a második táblánk sorainak száma megnövekedett - hiszen behoztuk hozzá az összes egyedi értéket. Kattintsunk rá jobb gombbal, majd a Context menüből válasszuk ki a Load To menüt: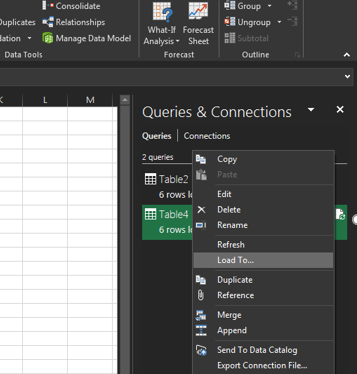 És ha megadtuk, hogy hova akarjuk betölteni az eredményt, meg is vagyunk a feladattal:
És ha megadtuk, hogy hova akarjuk betölteni az eredményt, meg is vagyunk a feladattal: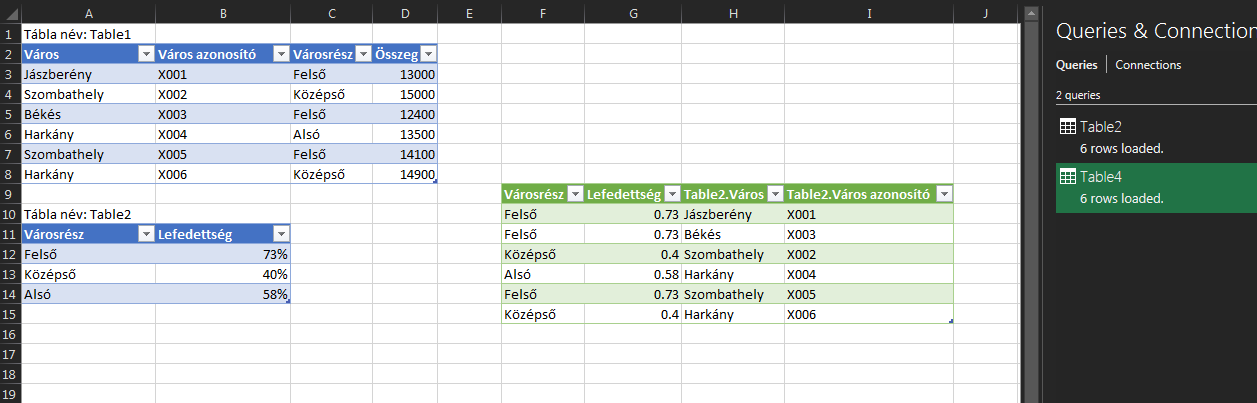
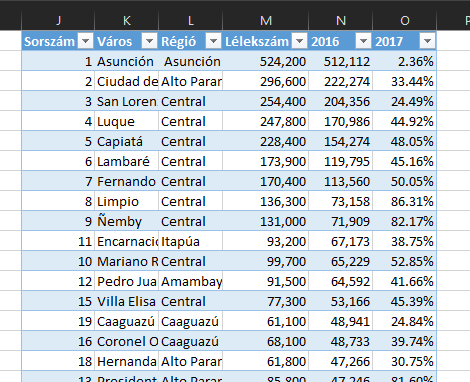 Ahogy látható, ez egy roppantul leegyszerűsített adathalmaz, paraguayi városok és régiók lélekszámát tartalmazza több évre vonatkozóan. Szóval ha megvan az adatunk a BI-ban, szépen vizualizáljuk azokat a számokat, amelyeket a céljaink érdekében szeretnénk megmutatni - hangsúlyozom, eléggé leegyszerűsített példáról beszélünk és a vizualizációval sem ragadtattam el magam:
Ahogy látható, ez egy roppantul leegyszerűsített adathalmaz, paraguayi városok és régiók lélekszámát tartalmazza több évre vonatkozóan. Szóval ha megvan az adatunk a BI-ban, szépen vizualizáljuk azokat a számokat, amelyeket a céljaink érdekében szeretnénk megmutatni - hangsúlyozom, eléggé leegyszerűsített példáról beszélünk és a vizualizációval sem ragadtattam el magam: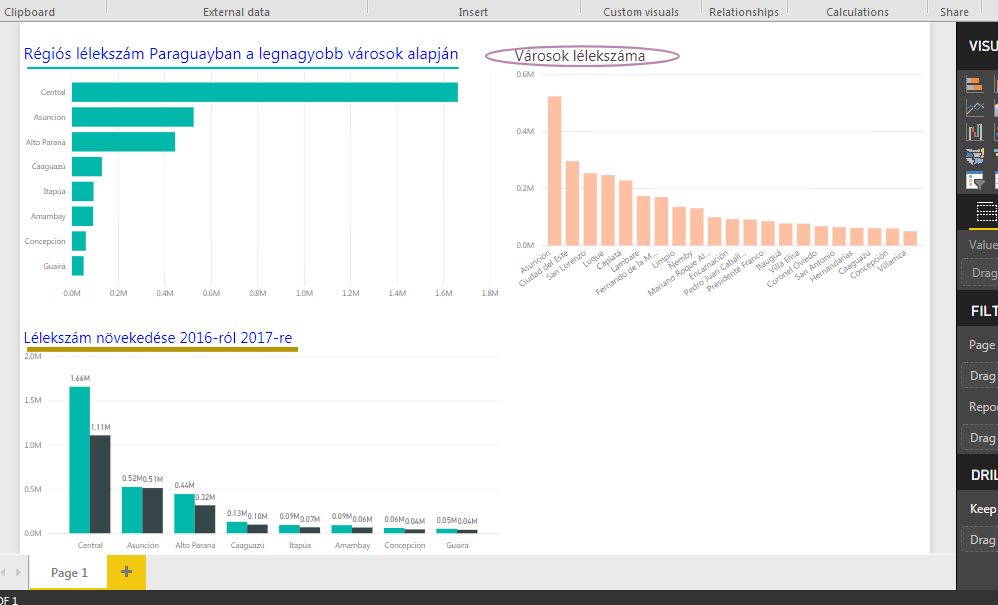 Amit most meg fogunk csinálni az egy Slicer, amivel azt akarjuk elérni, hogy a felhasználónk kiválaszthassa azt, hogy milyen adatokat akar megjeleníteni a chartokon, de azok közül is csak néhányon. A Slicert magát a Visualizations alatt találjuk az egyik jobboldali menüsoron:
Amit most meg fogunk csinálni az egy Slicer, amivel azt akarjuk elérni, hogy a felhasználónk kiválaszthassa azt, hogy milyen adatokat akar megjeleníteni a chartokon, de azok közül is csak néhányon. A Slicert magát a Visualizations alatt találjuk az egyik jobboldali menüsoron: Ha beszúrjuk és hozzáadjuk a Régiót, mint Fieldet, a következőt látjuk:
Ha beszúrjuk és hozzáadjuk a Régiót, mint Fieldet, a következőt látjuk: Tehát ezen ha mondjuk Asunción régióra kattintunk, akkor az összes chartunk és vizualizációnk szűrni fog Asunciónra. Még mielőtt azonban továbblépünk, kicsit formázzuk meg a Slicert, hogy ne lógjon ki annyira a dashboardból.
Tehát ezen ha mondjuk Asunción régióra kattintunk, akkor az összes chartunk és vizualizációnk szűrni fog Asunciónra. Még mielőtt azonban továbblépünk, kicsit formázzuk meg a Slicert, hogy ne lógjon ki annyira a dashboardból. Adjunk a Slicernek nevet a Title szekció alatt, adjunk hozzá Select All lehetőséget, rendezgessük kicsit a színeket és nagyjából elérünk egy ilyen helyzethez:
Adjunk a Slicernek nevet a Title szekció alatt, adjunk hozzá Select All lehetőséget, rendezgessük kicsit a színeket és nagyjából elérünk egy ilyen helyzethez: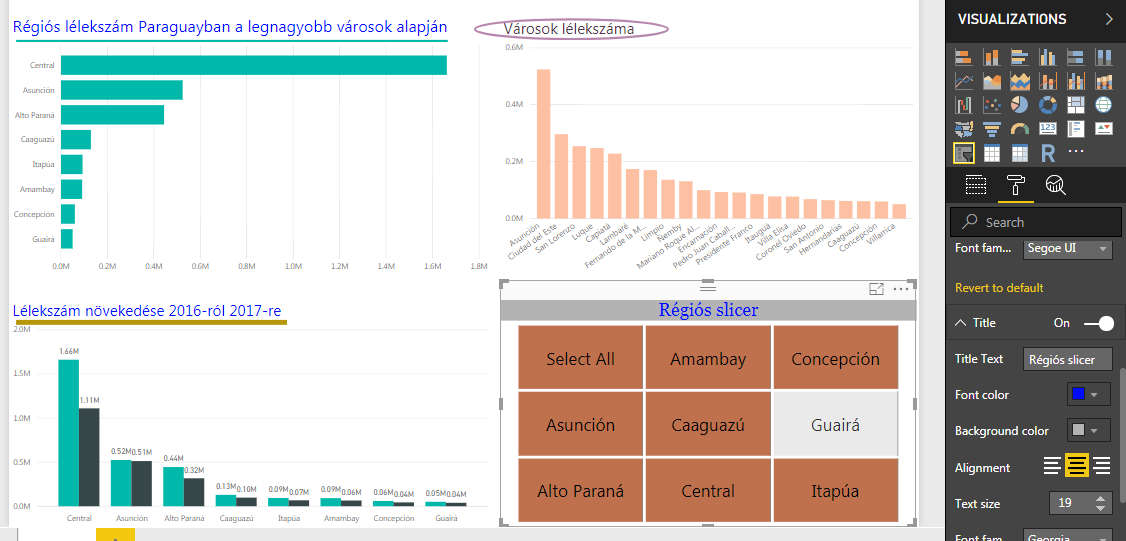 Tehát akár kész is lehetnénk, viszont beleütközünk egy problémába: ha bármelyik régióra kattintunk a slicerben, akkor az összes chartunk reagálni fog, valahogy így:
Tehát akár kész is lehetnénk, viszont beleütközünk egy problémába: ha bármelyik régióra kattintunk a slicerben, akkor az összes chartunk reagálni fog, valahogy így: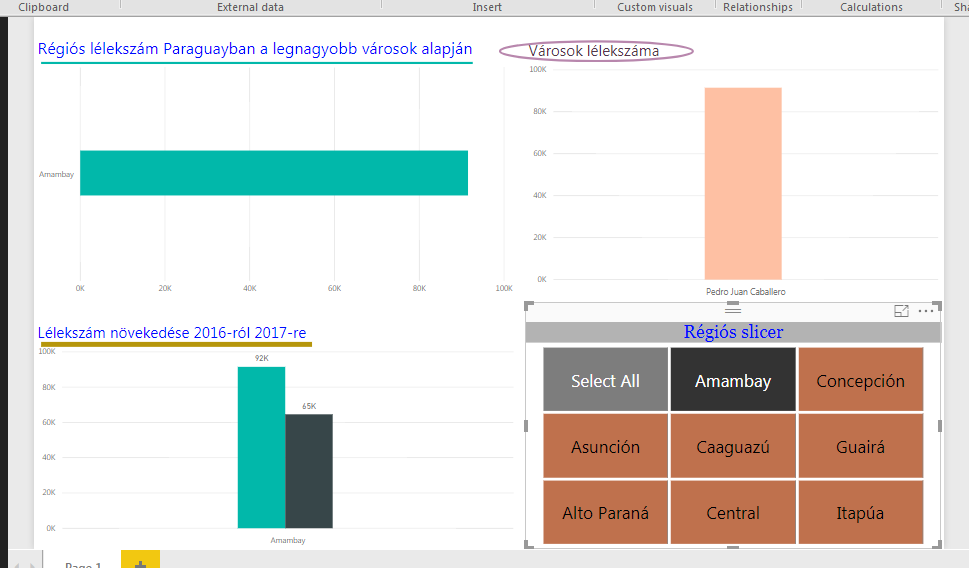 Ezt meg az esetek 99%-ában nem nagyon szeretnénk, úgyhogy kattintsunk a Format ribbonfül alatt az Interactions szekcióban az Edit Interactions funkcióra (fontos, hogy végig a Slicer legyen az aktív elemünk a munkalapon):
Ezt meg az esetek 99%-ában nem nagyon szeretnénk, úgyhogy kattintsunk a Format ribbonfül alatt az Interactions szekcióban az Edit Interactions funkcióra (fontos, hogy végig a Slicer legyen az aktív elemünk a munkalapon):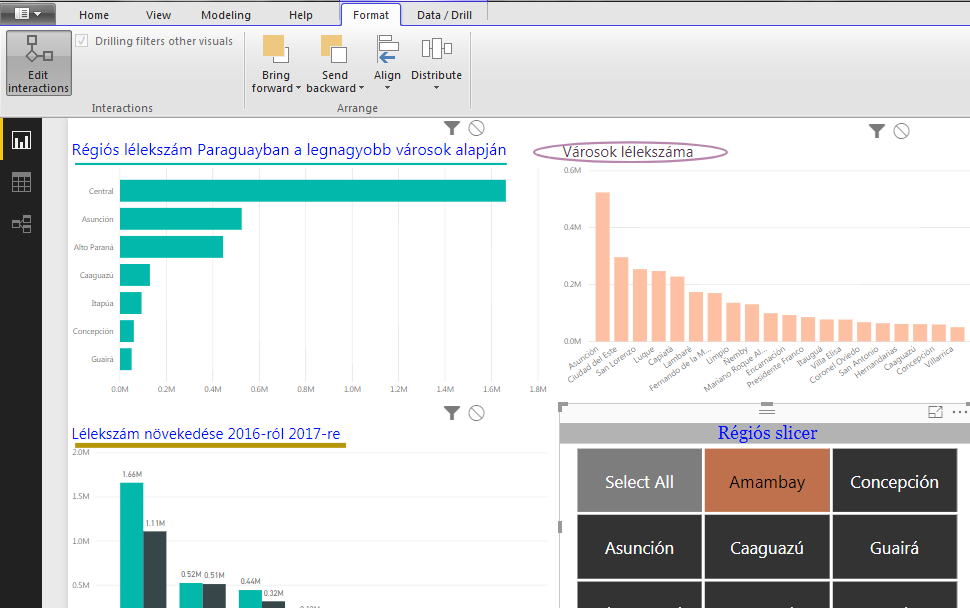 Látható a képen is, hogy a funkció aktiválásával megjelent egy apró szűrő-ikon és egy stop-ikon dashboardunk összes eleme felett. Szépen kattintgassunk a stop-ikonra azon elemek felett, amelyeket nem szeretnénk összekötni a Slicerrel és máris rendeztük a kapcsolódási pontokat. És most már látható is a Slicer eredménye, ha bármelyik régióra kattintunk:
Látható a képen is, hogy a funkció aktiválásával megjelent egy apró szűrő-ikon és egy stop-ikon dashboardunk összes eleme felett. Szépen kattintgassunk a stop-ikonra azon elemek felett, amelyeket nem szeretnénk összekötni a Slicerrel és máris rendeztük a kapcsolódási pontokat. És most már látható is a Slicer eredménye, ha bármelyik régióra kattintunk: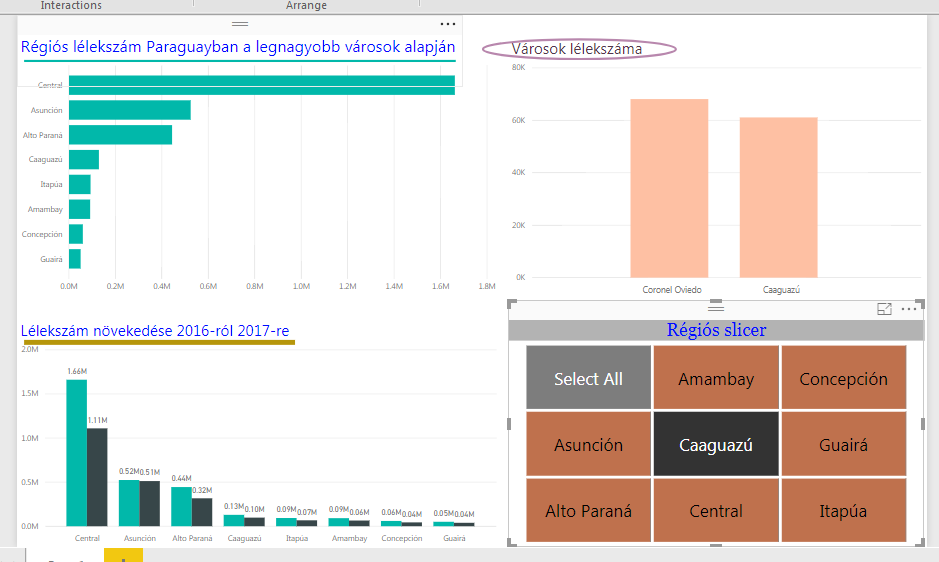 Én a két baloldali charton kapcsoltam ki az interakciót, így teljesen érthető módon csak a Városok lélekszáma chartom frissült a Slicerrel.
Én a két baloldali charton kapcsoltam ki az interakciót, így teljesen érthető módon csak a Városok lélekszáma chartom frissült a Slicerrel.