Bármilyen apró VBA-kódunk megírása során kétfajta hibát követhetünk el, egyrészt véthetünk szintaktikai (alaki) hibát, amikor a program nem felel meg a VBA szabályainak, illetve véthetünk szemantikai (tartalmi) hibát, amikor a program lefut, de rossz eredménnyel, vagy futás közben le is áll. Ezeknek vannak könnyen és kevésbé könnyen felismerhető előfordulásai, a mai posztban megnézünk egy roppant egyszerű kis kódszeletet, az általa tartalmazott hibát és persze a megoldásról is ejtünk szót.
Adott a következő roppant egyszerű kis tábla (a példa egyszerűsége ne tévesszen meg minket, sokkal komolyabb tábláknál és programoknál is belefuthatunk ebbe a hibába):
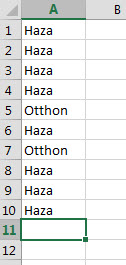 Valamilyen komplexebb programunkba beépítve vagy akár önmagában is azt szeretnénk elérni, hogy ha a felhasználó megad egy cellaértéket és megnyom egy gombot, akkor a megadott cellaértéknek megfelelő sorok kerüljenek törlésre.
Valamilyen komplexebb programunkba beépítve vagy akár önmagában is azt szeretnénk elérni, hogy ha a felhasználó megad egy cellaértéket és megnyom egy gombot, akkor a megadott cellaértéknek megfelelő sorok kerüljenek törlésre.
Erre elkészítjük a következő egyszerű kis kódot:
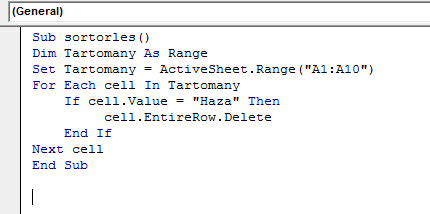
Sub sortorles()
Dim Tartomany As Range
Set Tartomany = ActiveSheet.Range("A1:A10")
For Each cell In Tartomany
If cell.Value = "Haza" Then
cell.EntireRow.Delete
End If
Next cell
End Sub
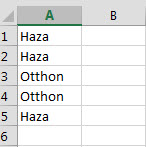
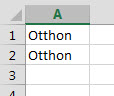
 Boldogok is vagyunk, ott van szépen a For ciklusunk, ami a megadott tartomány összes celláján fog végigmenni és megnézi a feltétel teljesülését majd ennek megfelelően jár el, ha szükséges - az összes soron már nem megyek végig, az eddigi posztok alapján feltételezem, hogy ez már senkinek nem okoz komoly problémát. Futtassuk hát le! Előzetes becslésünk alapján a példánál azt várnánk, hogy maradjon két darab Otthon értékünk, semmi más, ehelyett a következőt kapjuk:
Boldogok is vagyunk, ott van szépen a For ciklusunk, ami a megadott tartomány összes celláján fog végigmenni és megnézi a feltétel teljesülését majd ennek megfelelően jár el, ha szükséges - az összes soron már nem megyek végig, az eddigi posztok alapján feltételezem, hogy ez már senkinek nem okoz komoly problémát. Futtassuk hát le! Előzetes becslésünk alapján a példánál azt várnánk, hogy maradjon két darab Otthon értékünk, semmi más, ehelyett a következőt kapjuk:
 Vajon hol mehettünk félre? Hiszen szépen lefutott a program, nem is dobott hibát, mégsem az elvárt eredményt kaptuk. Azért a probléma önmagában egy tapasztalt VBA-felhasználónak nem okoz gondot, sőt valószínűleg elő sem idézi, de ettől függetlenül érdemes megvizsgálni ezt a kérdést.
Vajon hol mehettünk félre? Hiszen szépen lefutott a program, nem is dobott hibát, mégsem az elvárt eredményt kaptuk. Azért a probléma önmagában egy tapasztalt VBA-felhasználónak nem okoz gondot, sőt valószínűleg elő sem idézi, de ettől függetlenül érdemes megvizsgálni ezt a kérdést.
A probléma a For ciklus "előrehaladásában" rejlik, ugyanis a ciklus mindig csak a következő sort vizsgálja meg a feltételnek megfelelően, tehát ha a kettes sort törölte, akkor újra már nem vizsgálja meg, miközben pedig a törlés miatt a hármas sorunk beugrott a kettes helyére és ez a sor vizsgálatlan maradt.
Jópár különféle megoldás van ennek a problémának a kiküszöbölésére, talán a legegyszerűbb, ha nem is megyünk bele ebbe a ciklusba, hanem egyszerűen tartományként meghatározzuk a törlendő cellákat és úgy hajtjuk végre azt a lépést, akár ki is színezhetjük a cellák hátterét, majd szín alapján törölhetünk, de akár csinálhatjuk azt is, hogy a For ciklust visszafelé futtatjuk (hiszen akkor nem lesz "előrehaladási" probléma), mondjuk így:
Sub sortorles()
Dim Tartomany As Range
Set Tartomany = ActiveSheet.Range("A1:A10")
For i = 10 To 1 Step -1
If ActiveSheet.Cells(i, 1) = "Haza" Then
ActiveSheet.Cells(i, 1).EntireRow.Delete
End If
Next i
End Sub
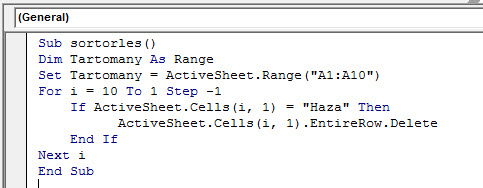
Ez sem túl bonyolult kód, ahogy látható, annyit változtattunk az előzőhöz képest, hogy az aktív sheetünk első oszlopában indulunk el a 10. cellától egyesével visszafelé az első celláig, és minden esetben megvizsgáljuk a ciklus éppen aktív cellájában a feltétel teljesülését majd ennek megfelelően törlünk.
Mondjuk ez 50 ezer sornál már nem lesz annyira szupergyors, úgyhogy inkább váltsunk ilyen esetekben egy másik megoldásra. Ötletek, javaslatok jöhetnek kommentben vagy akár Facebookon is.
 Ebből készítsünk most egy egyszerű Pivot-táblát, semmi extra, csak amit feltehetően rendszeresen csinálunk:
Ebből készítsünk most egy egyszerű Pivot-táblát, semmi extra, csak amit feltehetően rendszeresen csinálunk: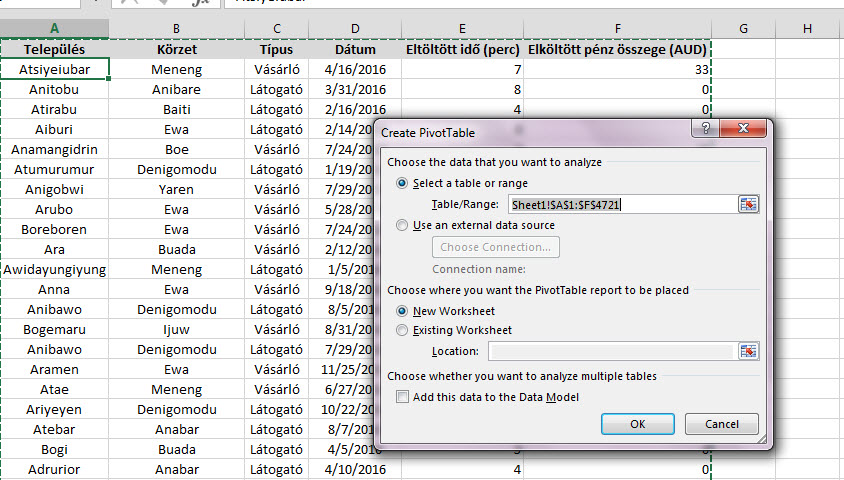 Példánkban most nincs nagy jelentősége a Pivot-felépítésének, egyszerűen szükségünk van egy Value oszlopra is, ami jelen esetben az elköltött ausztrál dollárok értéke lesz falvakra lebontva:
Példánkban most nincs nagy jelentősége a Pivot-felépítésének, egyszerűen szükségünk van egy Value oszlopra is, ami jelen esetben az elköltött ausztrál dollárok értéke lesz falvakra lebontva: És itt jön a poszt tényleges kérdése, azaz hogyan tudunk a Pivotban úgy szűrni, hogy kilistázzuk a 215-nél nagyobb értékeket például. A Pivot alapból Value oszlopban nem kínál fel nekünk szűrési lehetőséget:
És itt jön a poszt tényleges kérdése, azaz hogyan tudunk a Pivotban úgy szűrni, hogy kilistázzuk a 215-nél nagyobb értékeket például. A Pivot alapból Value oszlopban nem kínál fel nekünk szűrési lehetőséget: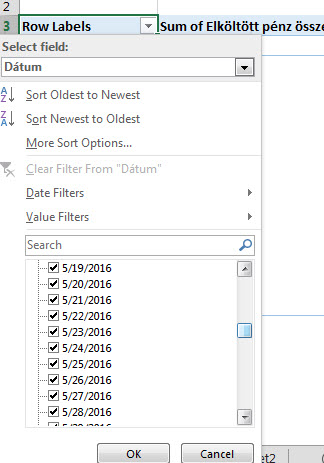 A Ribbonunk Data fülének Sort & Filter szekciójából tudunk szűrőt varázsolni a Value oszlopra is és így simán elérhetjük azt, amit akarunk:
A Ribbonunk Data fülének Sort & Filter szekciójából tudunk szűrőt varázsolni a Value oszlopra is és így simán elérhetjük azt, amit akarunk: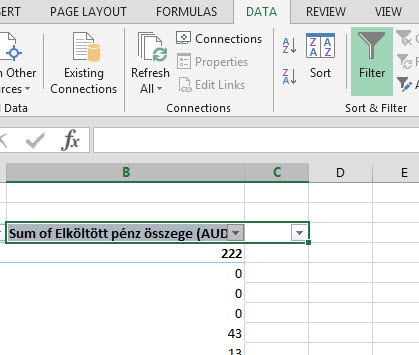 Itt már mehet a szűrés a megszokott módon, kisebb, nagyobb, átlag stb. feltételek mellett listázhatjuk értékeinket.
Itt már mehet a szűrés a megszokott módon, kisebb, nagyobb, átlag stb. feltételek mellett listázhatjuk értékeinket.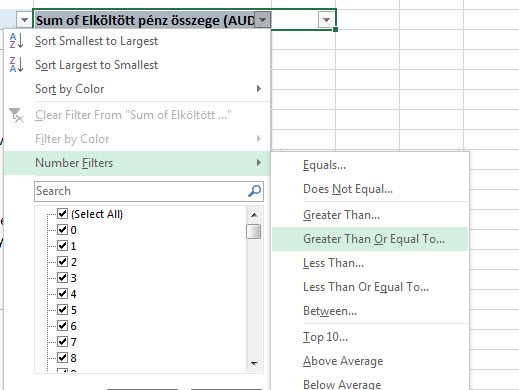 Viszont érdemes próbálgatni a Pivot által alapból felkínált szűrőre kattintva a Value Filters opciót is, mert ennek segítségével a Row címkékhez tartozó értékekre vonatkozó szűréseket tudunk beépíteni:
Viszont érdemes próbálgatni a Pivot által alapból felkínált szűrőre kattintva a Value Filters opciót is, mert ennek segítségével a Row címkékhez tartozó értékekre vonatkozó szűréseket tudunk beépíteni: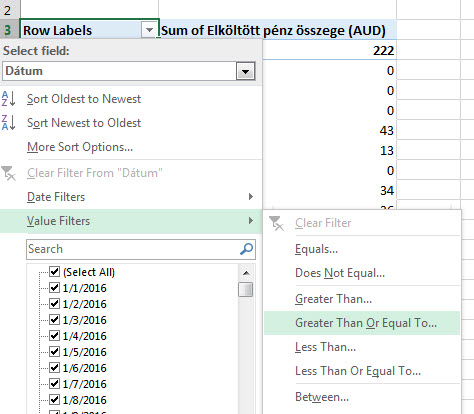 Csak egy a sok példából, a Value Filters segítségével könnyedén tudunk kisebb-nagyobb szűréseket végrehajtani a Value oszlop tartalmán, ami jelen példánk esetében talán nem egyértelműen mutatja meg hasznosságát, hiszen most Dátum szerint már csoportosítunk (Group) egyet a Pivotban és így a Subtotalra megy a szűrésünk, de ha nem csoportosított oszlopon szűrünk, akkor simán megy soronként a dolog. Ráadásul működik count és sum együttes használata esetén is (mi választhatjuk ki, mire szűrünk), sőt Column Labelre is rá tudjuk dobni, akkor pedig függőleges Total értékekre is szűrhetünk.
Csak egy a sok példából, a Value Filters segítségével könnyedén tudunk kisebb-nagyobb szűréseket végrehajtani a Value oszlop tartalmán, ami jelen példánk esetében talán nem egyértelműen mutatja meg hasznosságát, hiszen most Dátum szerint már csoportosítunk (Group) egyet a Pivotban és így a Subtotalra megy a szűrésünk, de ha nem csoportosított oszlopon szűrünk, akkor simán megy soronként a dolog. Ráadásul működik count és sum együttes használata esetén is (mi választhatjuk ki, mire szűrünk), sőt Column Labelre is rá tudjuk dobni, akkor pedig függőleges Total értékekre is szűrhetünk.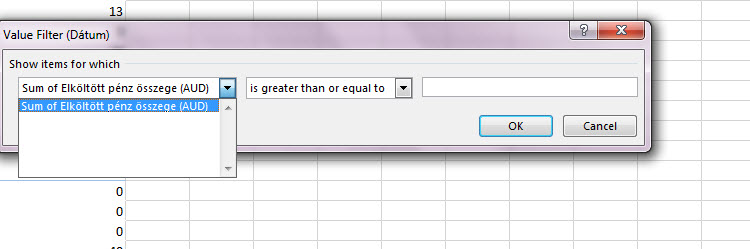
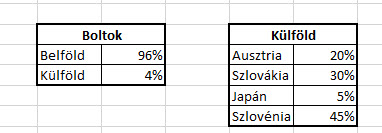 Ezen az egyszerű példán nagyjából annyit szeretnénk elérni, hogy legyen egy kördiagramunk két szelettel, az egyik a belföldet, a másik a külföldet mutatná, majd a külföldi cikkely egyértelmű kapcsolattal további bontásra kerülne országokra.
Ezen az egyszerű példán nagyjából annyit szeretnénk elérni, hogy legyen egy kördiagramunk két szelettel, az egyik a belföldet, a másik a külföldet mutatná, majd a külföldi cikkely egyértelmű kapcsolattal további bontásra kerülne országokra.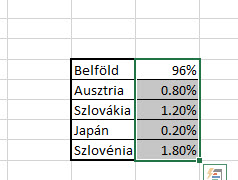 Ahogy látható, a külföldi 4%-ot a megfelelő arányban szétdobáltuk, de még mindig százalékos formátumban, azaz mondjuk Ausztria nem 20%-kal került kimutatásra, hanem az eredeti 4% ötödével.
Ahogy látható, a külföldi 4%-ot a megfelelő arányban szétdobáltuk, de még mindig százalékos formátumban, azaz mondjuk Ausztria nem 20%-kal került kimutatásra, hanem az eredeti 4% ötödével.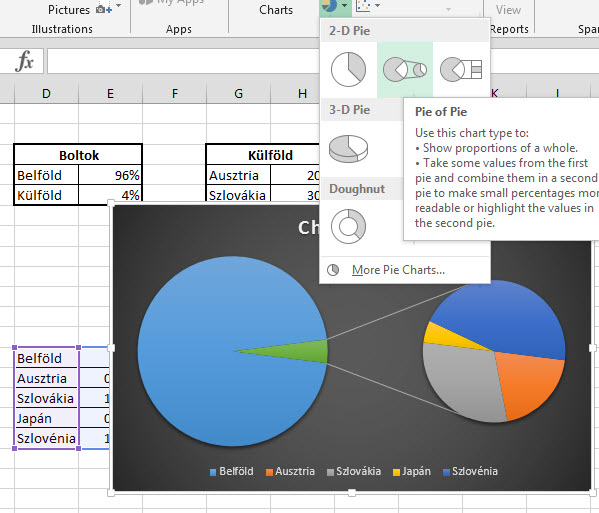 A Ribbonunk Insert füle alatt található Charts szekció kördiagram ikonjára kattintva válasszunk ki egy Pie of Pie chartot, aztán formázzuk olyanra, amilyenek az igényeink.
A Ribbonunk Insert füle alatt található Charts szekció kördiagram ikonjára kattintva válasszunk ki egy Pie of Pie chartot, aztán formázzuk olyanra, amilyenek az igényeink.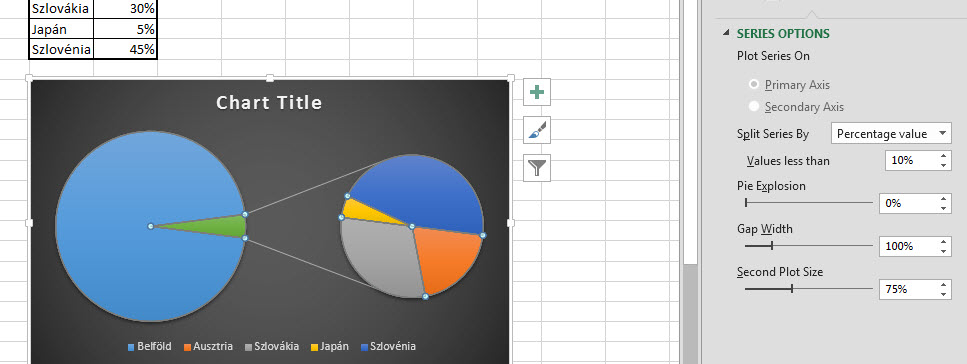 Ezzel tehát meg is lennénk, de hangsúlyozni kell, hogy ahogy minden kördiagram esetén, úgy most is igaz, hogy a hasznossági fok csak nagyon kevés körszelet esetén jelentősebb, komolyabb chartok vagy táblák esetén mindenképpen célszerű oszlopdiagramra váltani.
Ezzel tehát meg is lennénk, de hangsúlyozni kell, hogy ahogy minden kördiagram esetén, úgy most is igaz, hogy a hasznossági fok csak nagyon kevés körszelet esetén jelentősebb, komolyabb chartok vagy táblák esetén mindenképpen célszerű oszlopdiagramra váltani.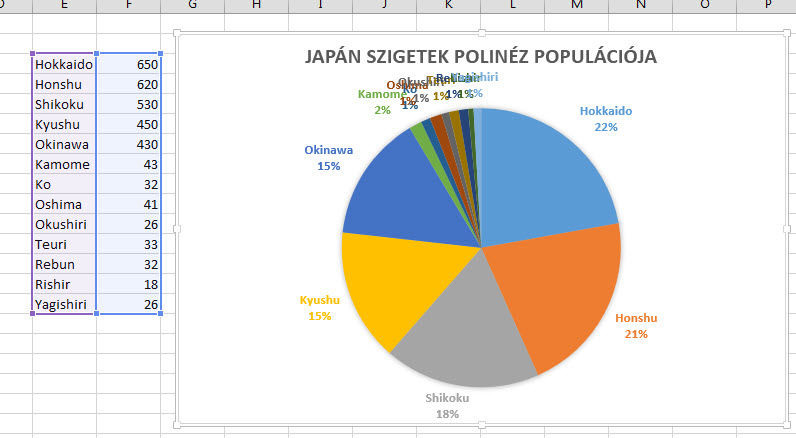 Tekintsünk most el attól, hogy lehetne ezt másképp is, a lényeg, hogy van egy szinte átláthatatlan kördiagramunk, ahol ráadásul még az értékek között is jelentős szórás áll fenn. Ennek tisztítására is felhasználhatjuk a Pie of Pie megoldást, méghozzá nagyjából úgy, hogy csinálunk a táblánkból először egy Pie of Pie diagramot, csak a kis értékeket megjelenítő másik kört elrejtjük és helyette egy összesített, EGYÉB kategória alatt futtatjuk végig a kis értékeket.
Tekintsünk most el attól, hogy lehetne ezt másképp is, a lényeg, hogy van egy szinte átláthatatlan kördiagramunk, ahol ráadásul még az értékek között is jelentős szórás áll fenn. Ennek tisztítására is felhasználhatjuk a Pie of Pie megoldást, méghozzá nagyjából úgy, hogy csinálunk a táblánkból először egy Pie of Pie diagramot, csak a kis értékeket megjelenítő másik kört elrejtjük és helyette egy összesített, EGYÉB kategória alatt futtatjuk végig a kis értékeket.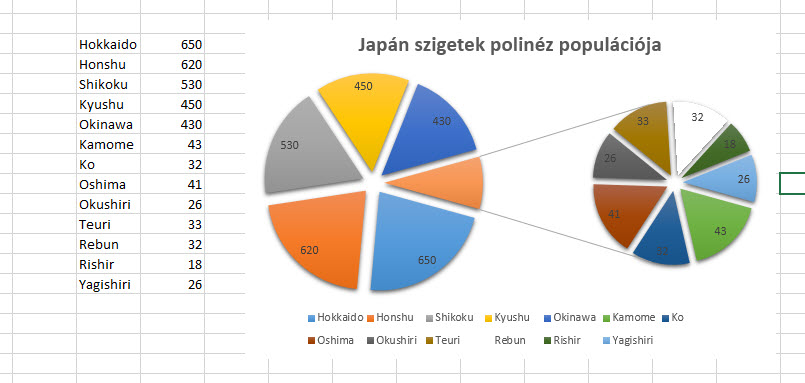 Következő lépésként egyesével végigkattintgatjuk a kis kördiagramunk cikkelyeit majd a kitöltést (FILL) és a keretet (BORDER) NONE-ra állítjuk, ezzel szépen el is tűnik majd a második diagram, de az első kördiagramban az apró értékek egyetlen cikkelybe tömörülnek továbbra is.
Következő lépésként egyesével végigkattintgatjuk a kis kördiagramunk cikkelyeit majd a kitöltést (FILL) és a keretet (BORDER) NONE-ra állítjuk, ezzel szépen el is tűnik majd a második diagram, de az első kördiagramban az apró értékek egyetlen cikkelybe tömörülnek továbbra is.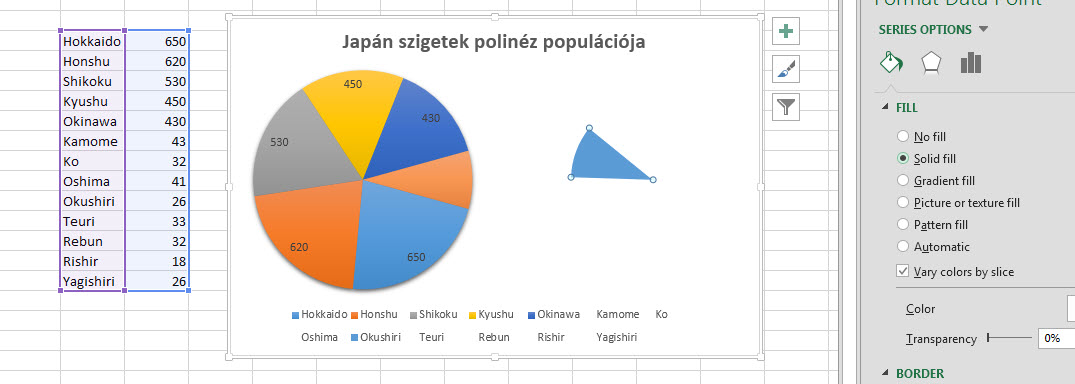 Ezután már nem kell mást tennünk, mint egyrészt a jelenleg már nem látszó második kördiagram méretét lekicsinyítenünk, hogy az első diagram középre kerüljön, másrészt a Legendet kell megformáznunk még egy kicsit, méghozzá úgy, hogy a már nem látható körcikkelyekre mutató címkéket eltávolítjuk és az apró értékeket tömörítő körcikkelyhez hozzáadunk egy, mondjuk "Other" névre hallgató címkét.
Ezután már nem kell mást tennünk, mint egyrészt a jelenleg már nem látszó második kördiagram méretét lekicsinyítenünk, hogy az első diagram középre kerüljön, másrészt a Legendet kell megformáznunk még egy kicsit, méghozzá úgy, hogy a már nem látható körcikkelyekre mutató címkéket eltávolítjuk és az apró értékeket tömörítő körcikkelyhez hozzáadunk egy, mondjuk "Other" névre hallgató címkét.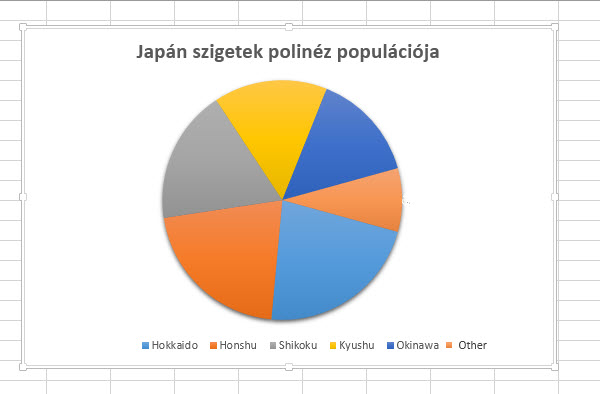 De hát ez a felhasználási mód nem igazán a legegyszerűbb módja ennek a megjelenítésnek, hiszen jóval egyszerűbb lett volna egy új táblázatot készíteni és "Other" sorba tömöríteni a megfelelő értékeket, deóe ettől függetlenül a lehetőségeinket próbálgatni tökéletes.
De hát ez a felhasználási mód nem igazán a legegyszerűbb módja ennek a megjelenítésnek, hiszen jóval egyszerűbb lett volna egy új táblázatot készíteni és "Other" sorba tömöríteni a megfelelő értékeket, deóe ettől függetlenül a lehetőségeinket próbálgatni tökéletes.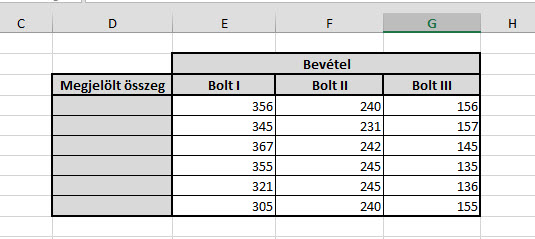
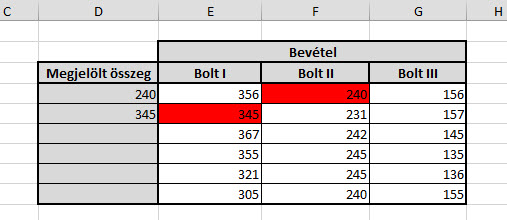 Sajnálatos módon az általam ismert lehetséges megoldások egyikével sem lehet ezt csak formulából megoldani, mindenképpen szükség van VBA-ra, bár túl hosszú kódra nem kell gondolnunk, szimplán csak a meghatározott cellánk színét szeretnénk visszanyerni.
Sajnálatos módon az általam ismert lehetséges megoldások egyikével sem lehet ezt csak formulából megoldani, mindenképpen szükség van VBA-ra, bár túl hosszú kódra nem kell gondolnunk, szimplán csak a meghatározott cellánk színét szeretnénk visszanyerni. Ebben a modulban fogjuk felépíteni a kis kódunkat, ami három részből áll. Először is nevezzük el a funkciónkat valamilyen néven és adjunk neki paramétereket is - a név segítségével tudjuk a formulák közül előszedni ezt a funkciót, a paraméterek pedig a formulák többségénél megszokott inputokat jelentik.
Ebben a modulban fogjuk felépíteni a kis kódunkat, ami három részből áll. Először is nevezzük el a funkciónkat valamilyen néven és adjunk neki paramétereket is - a név segítségével tudjuk a formulák közül előszedni ezt a funkciót, a paraméterek pedig a formulák többségénél megszokott inputokat jelentik.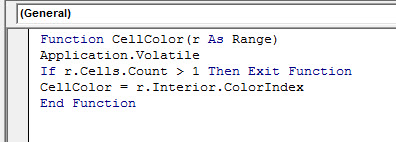 Ezután pedig ezt a formulát könnyedén felhasználhatjuk egy elemzésre, most már az eredeti munkalapon. Többféle megoldást el bírok képzelni, de a mostani példánál én három darab IF függvényt fogok CellColor funkcióval együtt egybeágyazni, hogy elérjem a kívánt eredményt:
Ezután pedig ezt a formulát könnyedén felhasználhatjuk egy elemzésre, most már az eredeti munkalapon. Többféle megoldást el bírok képzelni, de a mostani példánál én három darab IF függvényt fogok CellColor funkcióval együtt egybeágyazni, hogy elérjem a kívánt eredményt: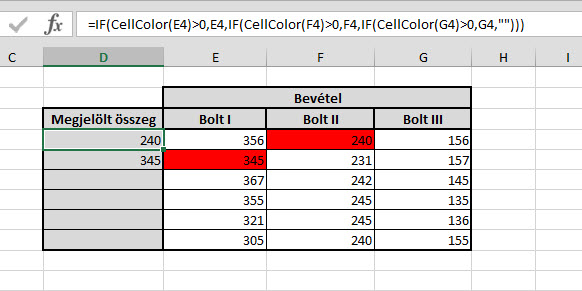 Ahogy korábban, minden építő jellegű kritikának, ötletnek, javaslatnak és főként más megoldásnak nagyon örülök!
Ahogy korábban, minden építő jellegű kritikának, ötletnek, javaslatnak és főként más megoldásnak nagyon örülök!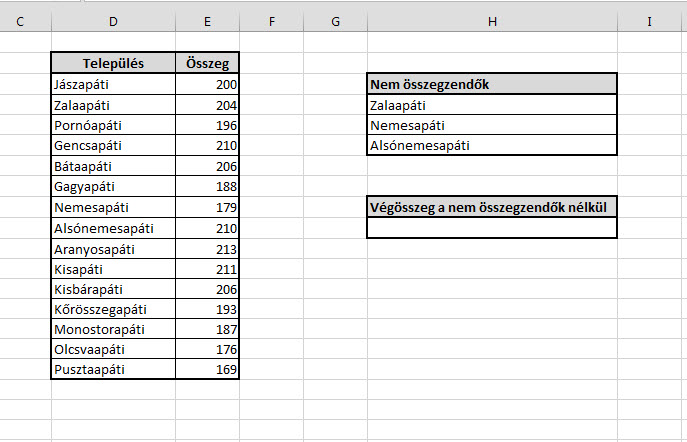 A célunk egyetlen képlettel annak elérése, hogy a Nem összegzendő táblázatban szereplő települések nélkül összegezzük a teljes táblánk értékeit. Ez tipikusan az a probléma, amelyre rengeteg megoldás létezik, nagyon favágó módszerrel készíthetünk például egy hatalmas, IF és SUM függvények egymásba ágyazásából álló formulát, de nyomhatunk egy PIVOT-Slicer megoldást is, kissé manuálisabb SUMIF felhasználás is szóba jöhet, de még akár a DSUM formulával is próbálkozhatunk. Ettől függetlenül a mostani megoldásban maradunk két függvénynél, az egyik az egyértelműen szükséges SUM, a másik pedig az Excel sokat megélt, titkos szuperfegyvere, a SUMPRODUCT.
A célunk egyetlen képlettel annak elérése, hogy a Nem összegzendő táblázatban szereplő települések nélkül összegezzük a teljes táblánk értékeit. Ez tipikusan az a probléma, amelyre rengeteg megoldás létezik, nagyon favágó módszerrel készíthetünk például egy hatalmas, IF és SUM függvények egymásba ágyazásából álló formulát, de nyomhatunk egy PIVOT-Slicer megoldást is, kissé manuálisabb SUMIF felhasználás is szóba jöhet, de még akár a DSUM formulával is próbálkozhatunk. Ettől függetlenül a mostani megoldásban maradunk két függvénynél, az egyik az egyértelműen szükséges SUM, a másik pedig az Excel sokat megélt, titkos szuperfegyvere, a SUMPRODUCT.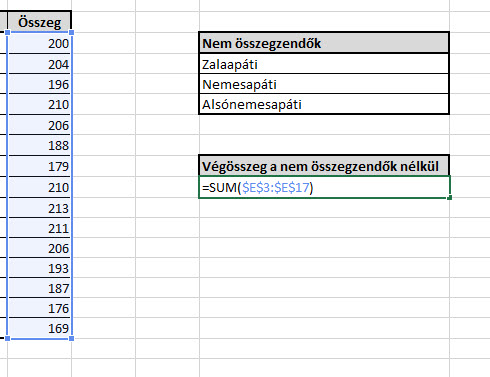 Na de hogyan összesítsük a kizárandó településeink értékeit? Ehhez hívjuk segítségül a COUNTIFS függvényt első körben, amely egy megadott tartományban megadja, hogy hány, az adott feltételnek megfelelő cellánk van, de ellentétben a COUNTIF formulával, ez több feltétel és tartomány elemzésére is képes.
Na de hogyan összesítsük a kizárandó településeink értékeit? Ehhez hívjuk segítségül a COUNTIFS függvényt első körben, amely egy megadott tartományban megadja, hogy hány, az adott feltételnek megfelelő cellánk van, de ellentétben a COUNTIF formulával, ez több feltétel és tartomány elemzésére is képes.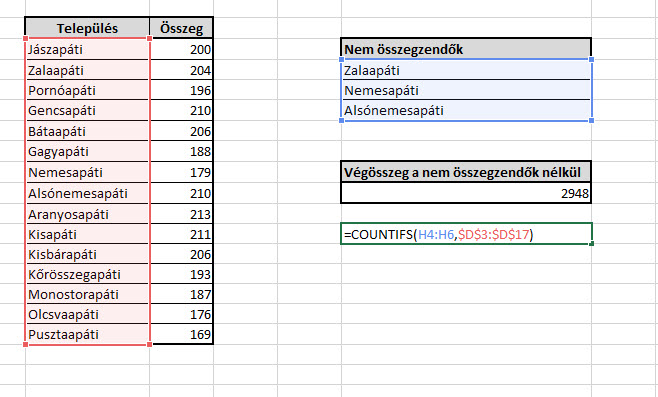 Hiszen nincs olyan cella, ami megfelelne mindhárom feltételnek. De még ne temessük a COUNTIFS-t, hiszen ezt a nulla szám ellenére még felhasználhatjuk egy SUMPRODUCT egyik paramétereként, mert azt már az itteni tucatnyi poszt után tudhatjuk, hogy ez a rendkívül sokoldalú tömbfüggvény (
Hiszen nincs olyan cella, ami megfelelne mindhárom feltételnek. De még ne temessük a COUNTIFS-t, hiszen ezt a nulla szám ellenére még felhasználhatjuk egy SUMPRODUCT egyik paramétereként, mert azt már az itteni tucatnyi poszt után tudhatjuk, hogy ez a rendkívül sokoldalú tömbfüggvény (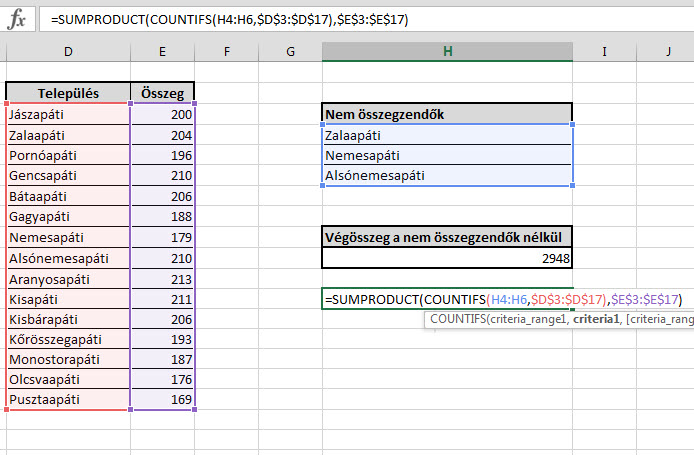
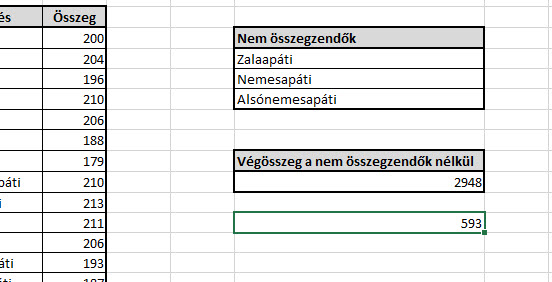 Ezután meg már csak ki kell vonnunk a legelső SUM-ból a az előbbi SUMPRODUCT-ot és meg is kapjuk az eredményünket:
Ezután meg már csak ki kell vonnunk a legelső SUM-ból a az előbbi SUMPRODUCT-ot és meg is kapjuk az eredményünket: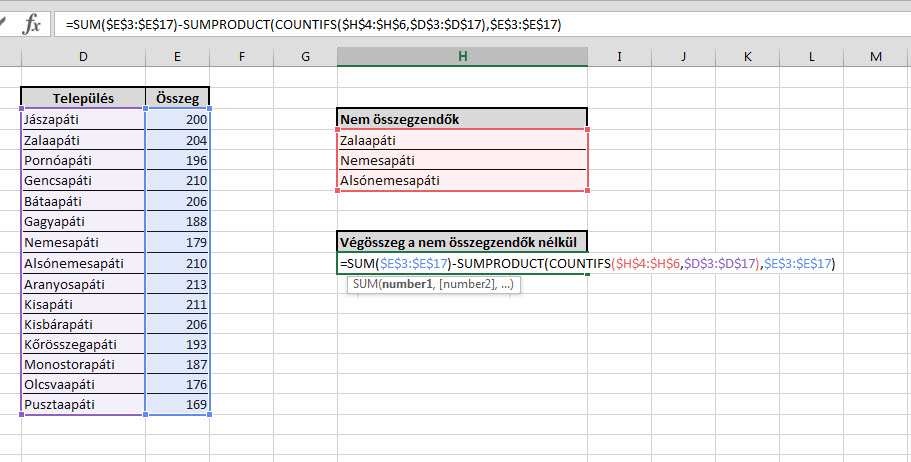 Persze ezt a hibák elkerülése érdekében átalakíthatjuk elnevezett tartományokra is, sokkal jobban szétszedhetjük és nagyobb táblákra optimalizálhatjuk a képletet, de alapvetően kiindulópontnak tökéletes. De jöhetnek kommentben más megoldások is, hiszen nekem sem a fenti volt az első, ami eszembe jutott ennél a kérdésnél, másrészt nem is biztos, hogy ez a legegyszerűbb válasz.
Persze ezt a hibák elkerülése érdekében átalakíthatjuk elnevezett tartományokra is, sokkal jobban szétszedhetjük és nagyobb táblákra optimalizálhatjuk a képletet, de alapvetően kiindulópontnak tökéletes. De jöhetnek kommentben más megoldások is, hiszen nekem sem a fenti volt az első, ami eszembe jutott ennél a kérdésnél, másrészt nem is biztos, hogy ez a legegyszerűbb válasz. Ezután értelemszerűen következnek a template mentésének beállításai, úgy mint név, fájlnév és leírás, illetve a legfontosabb lehetőség, az Include Content opció:
Ezután értelemszerűen következnek a template mentésének beállításai, úgy mint név, fájlnév és leírás, illetve a legfontosabb lehetőség, az Include Content opció: Ezt szépen leokézzuk és a következő ablakkal szembesülünk:
Ezt szépen leokézzuk és a következő ablakkal szembesülünk: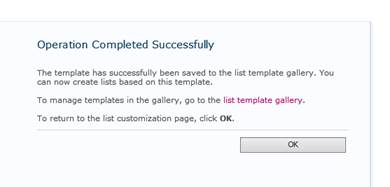 Az előbb megadott néven lementésre került a template-ünk az adott oldal List template könyvtárába, amely könyvtárat a megjelölt linken el is érhetünk és tegyünk is így, hiszen abból a könyvtárból fogjuk majd saját gépünkre lementeni ezt a templatet.
Az előbb megadott néven lementésre került a template-ünk az adott oldal List template könyvtárába, amely könyvtárat a megjelölt linken el is érhetünk és tegyünk is így, hiszen abból a könyvtárból fogjuk majd saját gépünkre lementeni ezt a templatet. Hol is tartunk most a folyamatban? Fogtunk egy létező SP-listánkat, majd tartalommal együtt templateként lementettük valahova a saját gépünkre.
Hol is tartunk most a folyamatban? Fogtunk egy létező SP-listánkat, majd tartalommal együtt templateként lementettük valahova a saját gépünkre. Belépve a könyvtárba, egyszerűen csak Upload Documenttel feltöltjük a kész listánkat:
Belépve a könyvtárba, egyszerűen csak Upload Documenttel feltöltjük a kész listánkat: Ezután pedig hozzunk létre egy új listát az oldalon, a lista template-jeként válasszuk ki a korábban feltöltöttet és láss csodát, kész is vagyunk.
Ezután pedig hozzunk létre egy új listát az oldalon, a lista template-jeként válasszuk ki a korábban feltöltöttet és láss csodát, kész is vagyunk.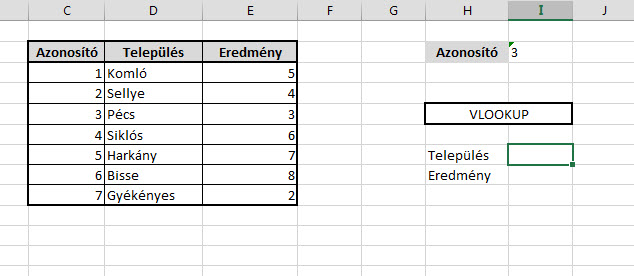 Csináljunk egy egyszerű VLOOKUP függvényt az Azonosító mezőnk alapján a Település felkeresésére:
Csináljunk egy egyszerű VLOOKUP függvényt az Azonosító mezőnk alapján a Település felkeresésére: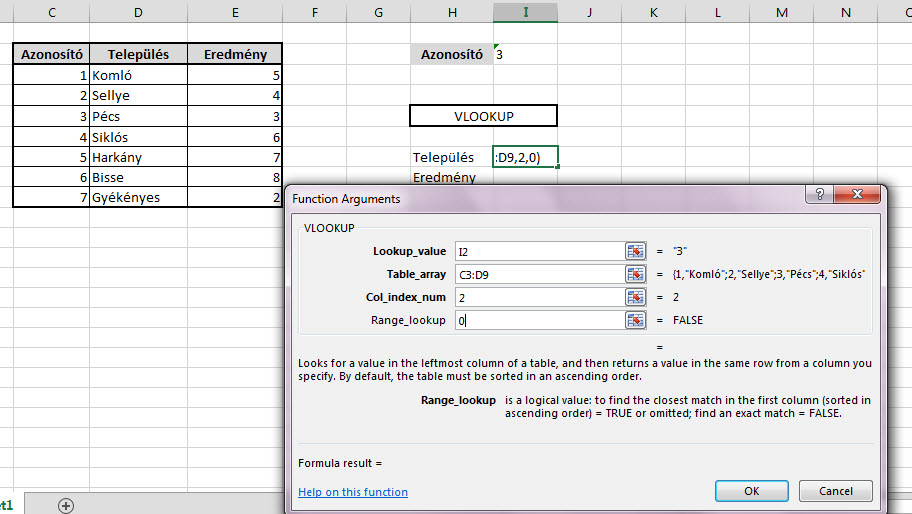 És lám, ott is a dühítő kis #N/A.
És lám, ott is a dühítő kis #N/A.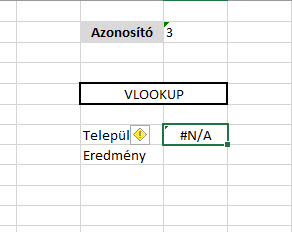 Persze erre nagyjából szinte mindenki azonnal rávágja, hogy formátumprobléma van, hiszen ahogy a kis zöld jelzésből látszik is az Azonosító mezőnk sarkában, ebben a mezőben Textként tárolunk számot, míg a táblánkban az azonosító számok Number formátumúak.
Persze erre nagyjából szinte mindenki azonnal rávágja, hogy formátumprobléma van, hiszen ahogy a kis zöld jelzésből látszik is az Azonosító mezőnk sarkában, ebben a mezőben Textként tárolunk számot, míg a táblánkban az azonosító számok Number formátumúak.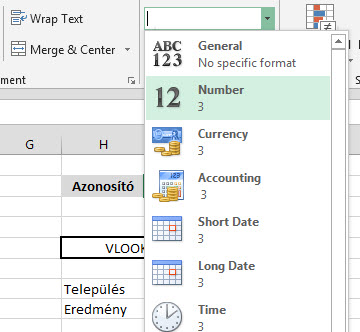 De hiába, nem történt semmi. Akkor mi is a probléma? Ha most viszont belekattintunk a hármas szám cellájába, akkor a formátum azonnal átvált ténylegesen Numberre és máris jó lesz a VLOOKUPunk eredménye:
De hiába, nem történt semmi. Akkor mi is a probléma? Ha most viszont belekattintunk a hármas szám cellájába, akkor a formátum azonnal átvált ténylegesen Numberre és máris jó lesz a VLOOKUPunk eredménye: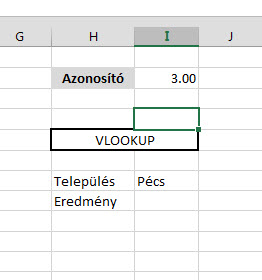 Na de ez most csak egyetlen cella, mi a helyzet ha több ezer soros tábláról van szó? Nem kattintgathatunk bele minden egyes cellába, hiszen arra senkinek nincs ideje.
Na de ez most csak egyetlen cella, mi a helyzet ha több ezer soros tábláról van szó? Nem kattintgathatunk bele minden egyes cellába, hiszen arra senkinek nincs ideje.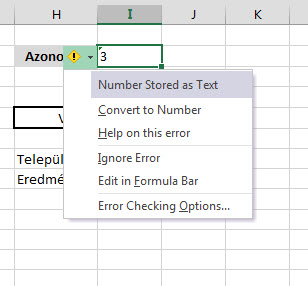 Kicsivel másabb a helyzet, ha fordítva nem működik a függvény, azaz a Lookup Value szám, a táblában szereplő azonosítók viszont Text formátumúak. Lásd lentebb:
Kicsivel másabb a helyzet, ha fordítva nem működik a függvény, azaz a Lookup Value szám, a táblában szereplő azonosítók viszont Text formátumúak. Lásd lentebb: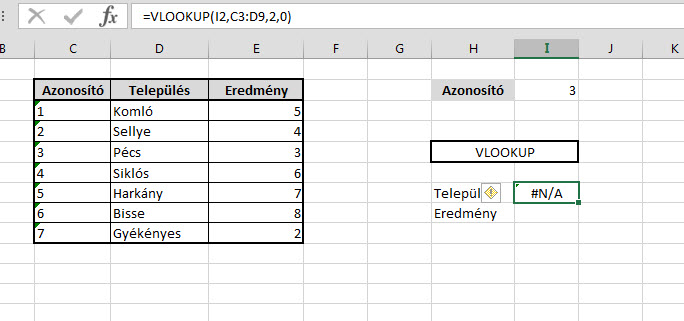 A sima átállítgatás itt még annyira sem működik, mint a másik esetben, ezért inkább megpróbáljuk a VLOOKUP formulát arra kényszeríteni, hogy már automatikusan alakítsa át a Lookup Valuet Text formátumra. Ezt pedig úgy tesszük meg, hogy a formulába, a Lookup Value mögé hozzáfűzünk egy szóközt, ezzel "kényszerítve" a kódot a bekeresendő érték textté való alakítására.
A sima átállítgatás itt még annyira sem működik, mint a másik esetben, ezért inkább megpróbáljuk a VLOOKUP formulát arra kényszeríteni, hogy már automatikusan alakítsa át a Lookup Valuet Text formátumra. Ezt pedig úgy tesszük meg, hogy a formulába, a Lookup Value mögé hozzáfűzünk egy szóközt, ezzel "kényszerítve" a kódot a bekeresendő érték textté való alakítására.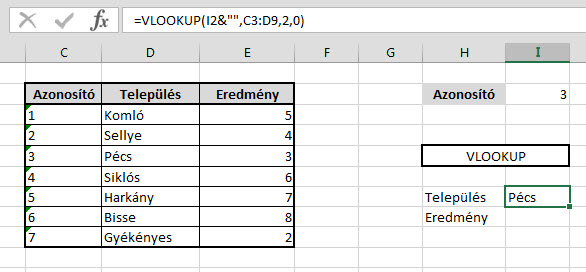
 A megoldás nem túl komplex és nem is igényel iszonyú nagy tudást sem, hiszen mindössze az Application.GetOpenFilename metódus ismerete (megspékelve persze azért alapvető VBA ismeretekkel is) elégséges ahhoz, hogy egy ilyen felugró ablakot összehozzunk.
A megoldás nem túl komplex és nem is igényel iszonyú nagy tudást sem, hiszen mindössze az Application.GetOpenFilename metódus ismerete (megspékelve persze azért alapvető VBA ismeretekkel is) elégséges ahhoz, hogy egy ilyen felugró ablakot összehozzunk. Következő lépésként aztán szépen meghatározzuk egy ChDrive utasítás segítségével az alapértelmezett meghajtónkat illetve könyvtárunkat:
Következő lépésként aztán szépen meghatározzuk egy ChDrive utasítás segítségével az alapértelmezett meghajtónkat illetve könyvtárunkat:
 Akárhogy is tesszük, Word dokumentumunk lementése majd újbóli megnyitása után előfordulhat, hogy hiába próbáljuk megnyitni az Excel doksit, a következő hibaüzenettel szembesülünk:
Akárhogy is tesszük, Word dokumentumunk lementése majd újbóli megnyitása után előfordulhat, hogy hiába próbáljuk megnyitni az Excel doksit, a következő hibaüzenettel szembesülünk:
 Ennek az ablaknak az alján válasszuk a Manage Add-insnél a COM Add-ineket:
Ennek az ablaknak az alján válasszuk a Manage Add-insnél a COM Add-ineket: Majd kapcsoljunk ki mindent:
Majd kapcsoljunk ki mindent: Tehetnék bele több oszlopot is, de a lényeg megértéséhez alapvetően elégséges lesz ennyi. Szóval első lépésként készítünk egy egyszerű Pivot-táblát:
Tehetnék bele több oszlopot is, de a lényeg megértéséhez alapvetően elégséges lesz ennyi. Szóval első lépésként készítünk egy egyszerű Pivot-táblát: Erre aztán szúrjunk be egy Slicert az Insert ribbonfül Filters szekciójában található Slicer menüpontból:
Erre aztán szúrjunk be egy Slicert az Insert ribbonfül Filters szekciójában található Slicer menüpontból: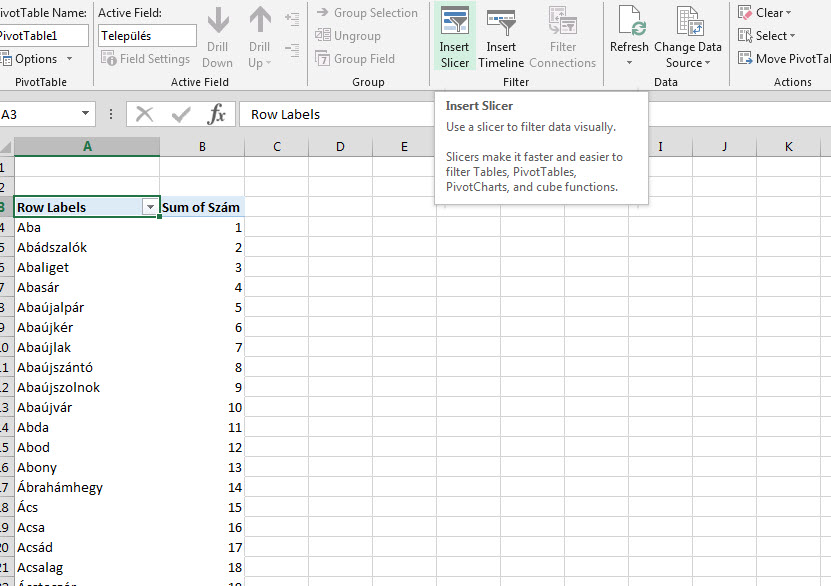 Ahogy látjuk, szépen meg is van az eredményünk, de ez a slicer már önmagában is rendkívül hosszú, nagyjából semmit nem nyertünk vele:
Ahogy látjuk, szépen meg is van az eredményünk, de ez a slicer már önmagában is rendkívül hosszú, nagyjából semmit nem nyertünk vele: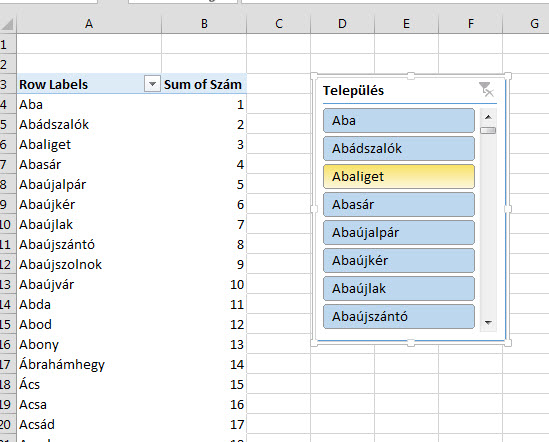
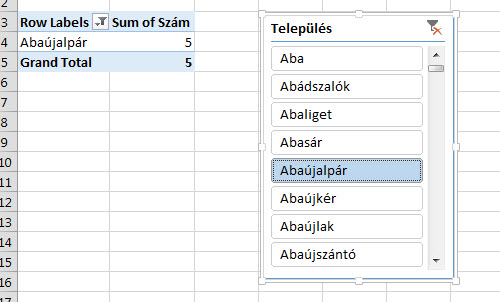 De ne essünk kétségbe, van arra mód, hogy egy slicerre egy másik slicert ráhúzva, kialakítsunk egy "slicer-szűrőt".
De ne essünk kétségbe, van arra mód, hogy egy slicerre egy másik slicert ráhúzva, kialakítsunk egy "slicer-szűrőt".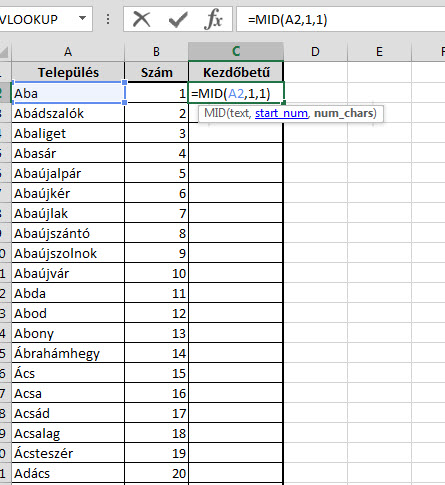 Ezután visszalépve a Pivothoz, a Pivottable Tools Analyze ribbonfül alatt válasszuk a Change Data Source funkciót és terjesszük ki a pivotunk forrásadatának területét:
Ezután visszalépve a Pivothoz, a Pivottable Tools Analyze ribbonfül alatt válasszuk a Change Data Source funkciót és terjesszük ki a pivotunk forrásadatának területét: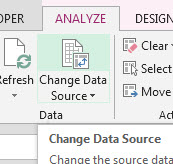
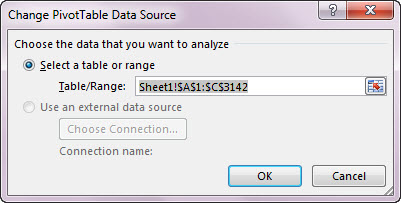 Ezután pedig a Slicer menüpontból szúrjunk be egy Slicert a kezdőbetűkre is:
Ezután pedig a Slicer menüpontból szúrjunk be egy Slicert a kezdőbetűkre is: Az eredmény magáért beszél, a kezdőbetűkre kattintva a Település slicer már magától szűrésre kerül, tehát jóval kisebb listával kell dolgoznunk:
Az eredmény magáért beszél, a kezdőbetűkre kattintva a Település slicer már magától szűrésre kerül, tehát jóval kisebb listával kell dolgoznunk: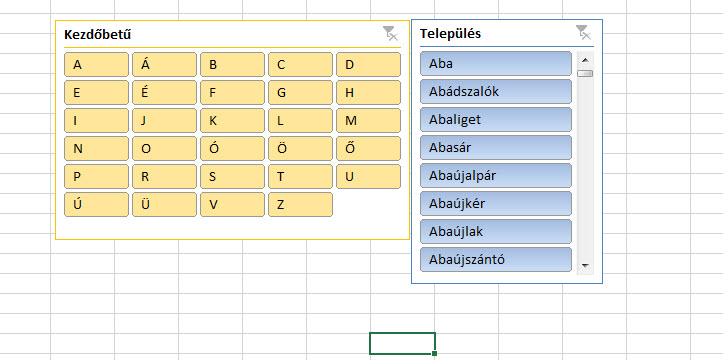
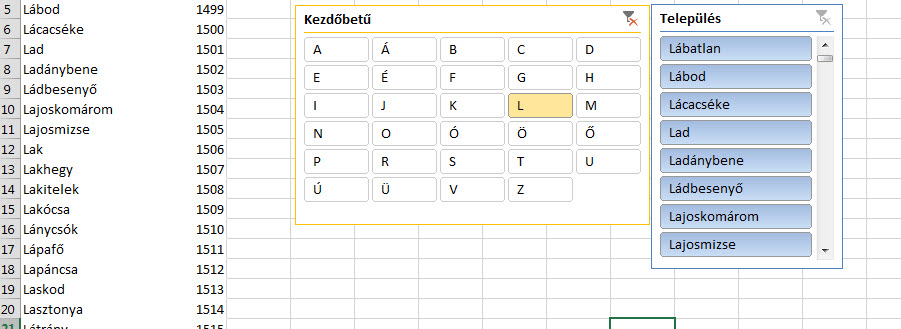 Értelemszerűen tekintsünk el most példám egyszerűségétől, a valódi értékét ennek a megoldásnak jóval komplikáltabb táblák esetén tudjuk értékelni igazán.
Értelemszerűen tekintsünk el most példám egyszerűségétől, a valódi értékét ennek a megoldásnak jóval komplikáltabb táblák esetén tudjuk értékelni igazán.