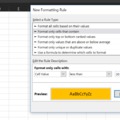
Itt az év vége, valószínűleg mindenki már csak egy kis feltöltődésre, kikapcsolódásra vágyik, úgyhogy ennek megfelelően most nem makrókról, Powerpointos rajzolgatásról, WORD-formátumokról lesz szó, hanem egy kis Excel-fejtörővel dolgoztatjuk meg agytekervényeinket.
A kérdés alapvetően roppant egyszerű: mondjuk meg egy cellában szereplő szövegről, hogy az ott szereplő szavak kezdőbetűi azonosak-e vagy sem, valahogy így:
 Az összes ilyen problémánál a megoldás kulcsa az ötlet, amellyel elérhetjük a célunkat, a megvalósítás már önmagában nem nagy dolog, gondoljunk csak vissza mondjuk az egy cellába beszúrható több link kérdésköréről. Az ötlet itt egy SUBSTITUTE függvény és egy IF egymásba ágyazása lenne a következő metódus szerint.
Az összes ilyen problémánál a megoldás kulcsa az ötlet, amellyel elérhetjük a célunkat, a megvalósítás már önmagában nem nagy dolog, gondoljunk csak vissza mondjuk az egy cellába beszúrható több link kérdésköréről. Az ötlet itt egy SUBSTITUTE függvény és egy IF egymásba ágyazása lenne a következő metódus szerint.
Annak érdekében, hogy a nagy és kisbetűk ne számítsanak, első lépésként UPPER függvény segítségével A oszlopban szereplő szövegünk minden betűjét nagybetűvé varázsoljuk:
=UPPER(A1)
Ezután jön a képbe a SUBSTITUTE függvény, amely az első paramétereként megadott szövegben, a második paramétereként megadott szövegrészt a harmadik paramétereként megadott szövegrészre cseréli le. A mi esetünkben megfogjuk a nagybetűs A1 cellánkat, majd a szóközök A1 szövegünk első karakterével összefűzött tartalmát lecseréljük szimplán semmire (""). A szóközöket A1 szövegünk első karakterével a következő módon fűzhetjük össze:
=" "&LEFT(UPPER(A1),1)
Használhatunk CONCATENATE függvényt is értelemszerűen, a LEFT függvényről pedig tudjuk, hogy az első paramétereként megadott szöveg bal oldalából vág le annyi karaktert, amennyit második paraméterként megadunk.
Szóval ezt kell most szépen lecserélnünk az UPPER(A1) szövegben semmire:
=SUBSTITUTE(UPPER(A1)," "&LEFT(UPPER(A1),1),"")
Itt tartunk most:
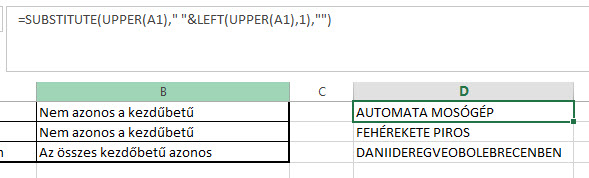 Csak a megértés szempontjából a megoldás következő részét egy újabb oszlopban fogom felvázolni a kis táblázatunkban, amely rész nem más lesz, mint a fenti SUBSTITUTE megismétlése, azzal a különbséggel, hogy most nem fűzzük össze a szóközöket az első karakterekkel, szimplán lecseréljük őket semmire (""):
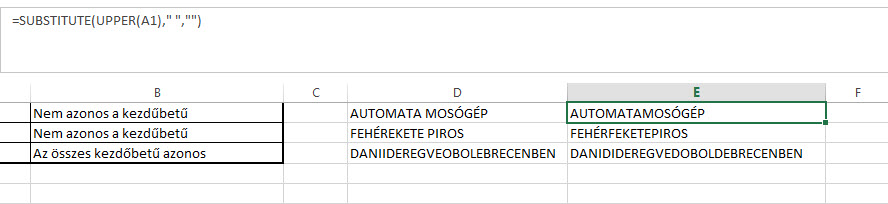
Csak a megértés szempontjából a megoldás következő részét egy újabb oszlopban fogom felvázolni a kis táblázatunkban, amely rész nem más lesz, mint a fenti SUBSTITUTE megismétlése, azzal a különbséggel, hogy most nem fűzzük össze a szóközöket az első karakterekkel, szimplán lecseréljük őket semmire (""):
=SUBSTITUTE(UPPER(A1)," ","")
 Következő lépésként egy LEN függvényt kell beiktatnunk az eddigi megoldás-részeinkbe, ami ugyebár nem csinál mást, mint a paramétereként megadott szöveg karakterszámát adja vissza (ez mondjuk trailing space levadászására is jó lehet).
Következő lépésként egy LEN függvényt kell beiktatnunk az eddigi megoldás-részeinkbe, ami ugyebár nem csinál mást, mint a paramétereként megadott szöveg karakterszámát adja vissza (ez mondjuk trailing space levadászására is jó lehet).
Mindkét fentebb említett SUBSTITUTE függvénystruktúránk hosszúságát határozzuk meg, majd vonjuk ki őket az eredeti szövegünk hosszúságából - ergó amit így megkapunk, az egyrészt az eltávolított szóközeink és kezdőbetűink száma másrészt szimplán a szóközeink száma:
=LEN(UPPER(A1))-LEN(SUBSTITUTE(UPPER(A1)," "&LEFT(UPPER(A1),1),""))
=LEN(UPPER(A1))-LEN(SUBSTITUTE(UPPER(A1)," ",""))
Szóval most már van két számunk:
 Mihez kezdjünk ezzel? A kulcs abban rejlik, hogy az első karaktereket is eltávolító megoldás-részünket még el kell osztanunk kettővel is, hiszen azzal meg tudjuk határozni, hogy pontosan hány kezdőbetűt vettünk ki amiatt, hogy megegyezik az első szó kezdőbetűjével:
Mihez kezdjünk ezzel? A kulcs abban rejlik, hogy az első karaktereket is eltávolító megoldás-részünket még el kell osztanunk kettővel is, hiszen azzal meg tudjuk határozni, hogy pontosan hány kezdőbetűt vettünk ki amiatt, hogy megegyezik az első szó kezdőbetűjével:
=(LEN(UPPER(A1))-LEN(SUBSTITUTE(UPPER(A1)," "&LEFT(UPPER(A1),1),"")))/2
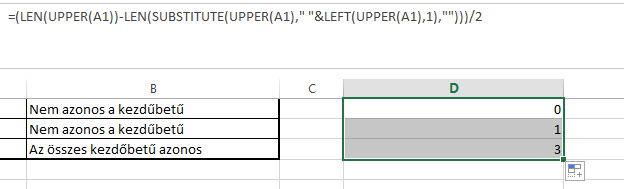 Ugyebár ha az összes kezdőbetű azonos, akkor pontosan azt a számot kapjuk meg, ahány szóközünk van a szövegben - következésképpen már csak meg kell vizsgálnunk, hogy az első és a második megoldás-részünk megegyezik-e, mert ha igen, az azt jelenti, hogy minden kezdőbetűnk azonos a szövegben. Ezt a vizsgálatot pedig egy szimpla IF függvénnyel tudjuk elvégezni így:
Ugyebár ha az összes kezdőbetű azonos, akkor pontosan azt a számot kapjuk meg, ahány szóközünk van a szövegben - következésképpen már csak meg kell vizsgálnunk, hogy az első és a második megoldás-részünk megegyezik-e, mert ha igen, az azt jelenti, hogy minden kezdőbetűnk azonos a szövegben. Ezt a vizsgálatot pedig egy szimpla IF függvénnyel tudjuk elvégezni így:
=IF((LEN(UPPER(A1))-LEN(SUBSTITUTE(UPPER(A1)," "&LEFT(UPPER(A1),1),"")))/2=LEN(UPPER(A1))-LEN(SUBSTITUTE(UPPER(A1)," ","")),"Az összes kezdőbetű azonos","Nem azonos a kezdőbetű")